docker常用命令以及安装mysql Veröffentlicht am 2019-05-08 | Bearbeitet am 2019-06-11 | in Docker1.简介Docker是一个开源的应用容器引擎;是一个轻量级容器技术;Docker支持将软件编译成一个镜像;然后在镜像中各种软件做好配置,将镜像发布出去,其他使用者可以直接使用这个镜像;运行中的这个镜像称为容器,容器启动是非常快速的。Weiterlesen »
Kudu与Spark 生产最佳实践 Veröffentlicht am 2019-05-07 | Bearbeitet am 2019-06-14 | in Spark OtherWeiterlesen »
捷报:连续2周若泽数据第7-12名学员喜捷offer(含蚂蚁金服) Veröffentlicht am 2019-04-29 | Bearbeitet am 2019-06-18 | in 高薪就业我们不做过多宣传,因为我们是若泽数据,企业在职。(现在其他机构也效仿我们说,企业在职,哎,很无语了,擦亮眼睛很重要!)Weiterlesen »
生产常用Spark累加器剖析之二 Veröffentlicht am 2019-04-26 | Bearbeitet am 2019-06-14 | in Spark OtherDriver端Driver端初始化构建Accumulator并初始化,同时完成了Accumulator注册,Accumulators.register(this)时Accumulator会在序列化后发送到Executor端Driver接收到ResultTask完成的状态更新后,会去更新Value的值 然后在Action操作执行后就可以获取到Accumulator的值了Executor端Executor端接收到Task之后会进行反序列化操作,反序列化得到RDD和function。同时在反序列化的同时也去反序列化Accumulator(在readObject方法中完成),同时也会向TaskContext完成注册完成任务计算之后,随着Task结果一起返回给DriverWeiterlesen »
spark2.4.2详细介绍 Veröffentlicht am 2019-04-23 | Bearbeitet am 2019-06-01 | in Spark OtherSpark发布了最新的版本spark-2.4.2根据官网介绍,此版本对于使用spark2.4的用户来说帮助是巨大的版本介绍Spark2.4.2是一个包含稳定性修复的维护版本。 此版本基于Spark2.4维护分支。 我们强烈建议所有2.4用户升级到此稳定版本。Weiterlesen »
捷报:上周若泽数据6名学员喜捷offer(含腾讯) Veröffentlicht am 2019-04-22 | Bearbeitet am 2019-06-18 | in 高薪就业我们不做过多宣传,因为我们是若泽数据,企业在职。(现在其他机构也效仿我们说,企业在职,哎,很无语了,擦亮眼睛很重要!)Weiterlesen »
生产常用Spark累加器剖析之一 Veröffentlicht am 2019-04-19 | Bearbeitet am 2019-06-14 | in Spark Other由于最近在项目中需要用到Spark的累加器,同时需要自己去自定义实现Spark的累加器,从而满足生产上的需求。对此,对Spark的累加器实现机制进行了追踪学习。本系列文章,将从以下几个方面入手,对Spark累加器进行剖析:Spark累加器的基本概念累加器的重点类构成累加器的源码解析累加器的执行过程累加器使用中的坑自定义累加器的实现Weiterlesen »
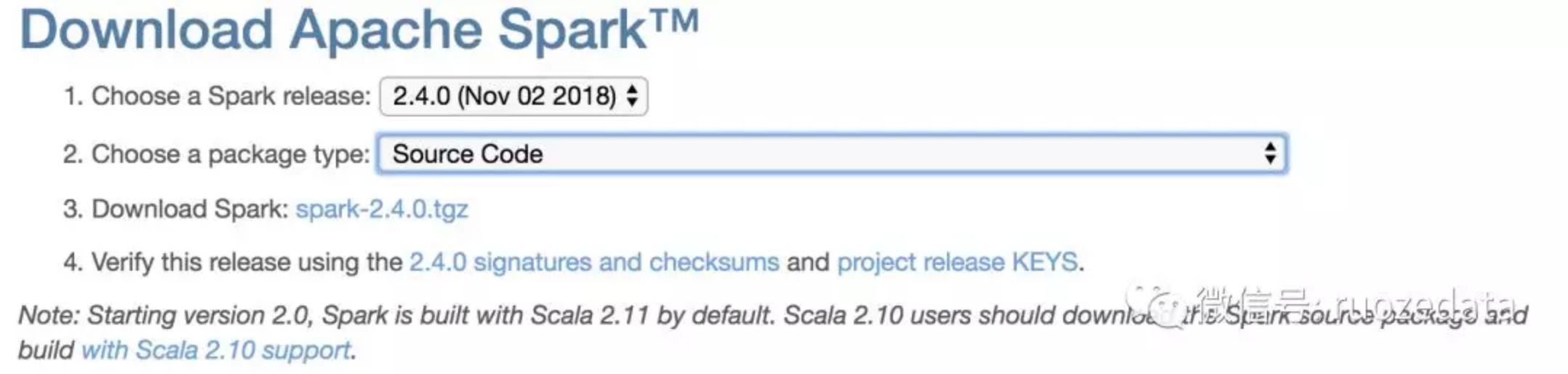
生产Spark2.4.0如何Debug源代码 Veröffentlicht am 2019-04-17 | Bearbeitet am 2019-06-14 | in Spark Other源码获取与编译直接从Spark官网获取源码或者从GitHub获取下载源码1wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0.tgz解压源码1tar -zxf spark-2.4.0.tgzWeiterlesen »