一.数据源同步中间件:
Canal
https://github.com/alibaba/canal
https://github.com/Hackeruncle/syncClient
通过Spark SQL JDBC 方法,抽取Oracle表数据。
大数据开发人员反映,使用效果上列表分区优于散列分区。但Spark SQL JDBC方法只支持数字类型分区,而业务表的列表分区字段是个字符串。目前Oracle表使用列表分区,对省级代码分 区。
参考 http://spark.apache.org/docs/1.6.2/sql-programming-guide.html#jdbc-to-other-databases
按照不同部门作为分区,导数据到目标表
71.创建静态分区表:
1 | create table emp_static_partition( |
2.插入数据:
1 | hive>insert into table emp_static_partition partition(deptno=10) |
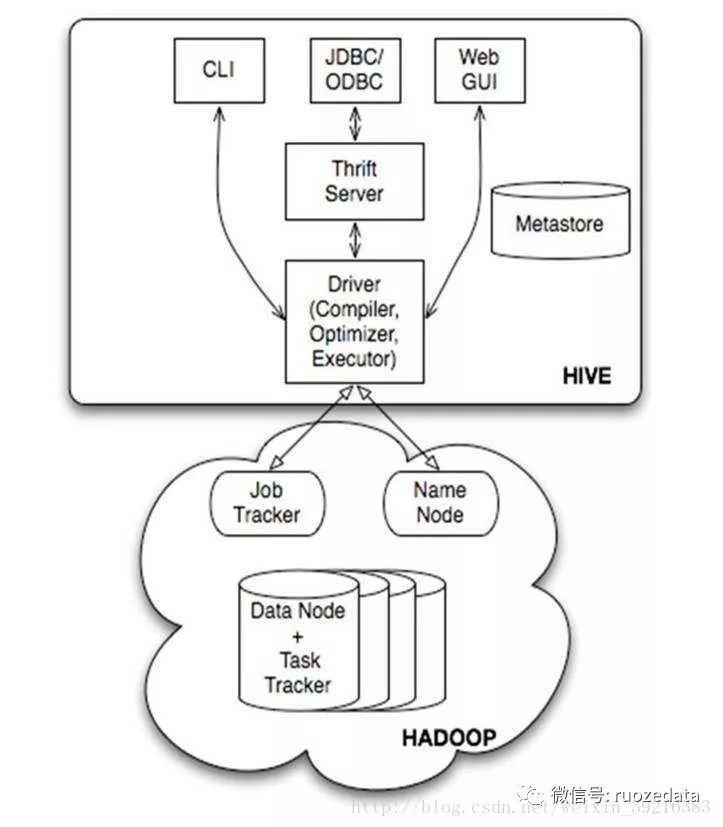
在了解内部表和外部表区别前,
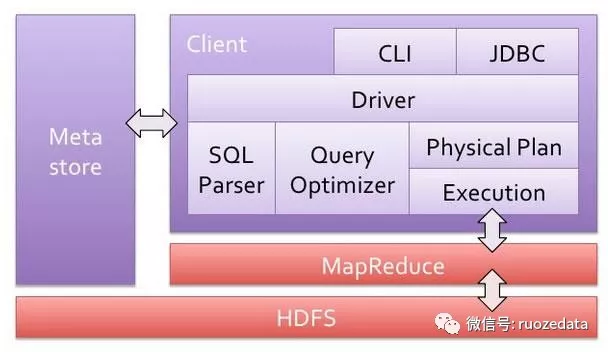
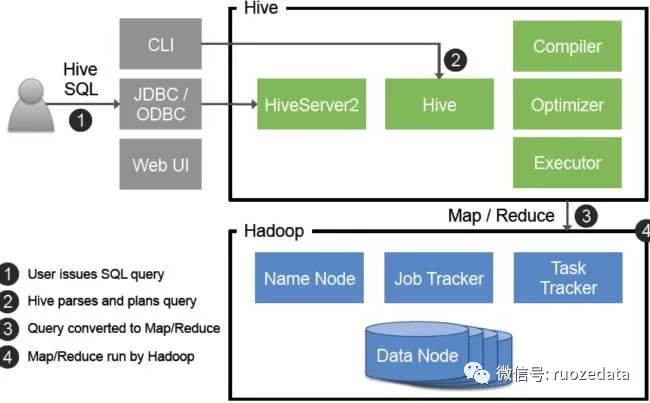
我们需要先了解一下Hive架构 :
当年我是做C#+Java软件开发,然后考取OCP来了上海,立志要做一名DBA。只记得当年试用期刚过时,阴差阳错轮到我负责公司的大数据平台这块,刚开始很痛苦,一个陌生的行业,一个讨论的小伙伴都没有,一份现成资料都没有,心情焦虑。后来我调整心态,从DB转移到对大数据的研究,决定啃下这块硬骨头,把它嚼碎,把它消化吸收。
由于当时公司都是CDH环境,刚开始安装卡了很久都过不去,后面选择在线安装,很慢,有时需要1天。后来安装HDFS ,YARN,HIVE组件,不过对它们不理解,不明白,有时很困惑。这样的过程大概持续三个月了。
Hive自定义函数(UDF)的部署使用,你会吗,三种方式!
本地开发环境:IntelliJ IDEA+Maven3.3.9
若泽大数据,带你全面剖析Hive DDL!