Livy安装部署
官网:http://livy.incubator.apache.org/get-started/
Download
1 | [hadoop@hadoop001 software]$ wget http://mirrors.hust.edu.cn/apache/incubator/livy/0.5.0-incubating/livy-0.5.0-incubating-bin.zip |
修改日志,使其信息能打印在控制台上
1 | [hadoop@hadoop001 conf]$vim log4j.properties |
启动Livy
1 | [hadoop@hadoop001 livy-0.5.0-incubating-bin]$ ./bin/livy-server |
会报错,信息如下
1 | Exception in thread "main" java.io.IOException: Cannot write log directory /opt/app/livy-0.5.0-incubating-bin/logs |
解决办法
权限问题,需要手动创建logs目录
1 | [hadoop@hadoop001 livy-0.5.0-incubating-bin]$ mkdir logs |
启动成功后进行Web访问:
1 | 19/08/29 22:26:20 INFO LineBufferedStream: stdout: Welcome to |
Livy配置文件解读
- livy.conf:配置了一些server的信息
spark-blacklist.conf
会列出来一些spark配置中的一些东西,这些东西用户是不允许被修改掉的 给用户的一些东西,有些是不能改的,比如:内存大小的设置、executor的设置 这些给用户改,是不放心的;因此有些东西必然是不能够暴露的log4j.properties:日志信息
livy.conf的配置如下:
1 | [hadoop@hadoop001 conf]$ cp livy.conf.template livy.conf |
架构篇
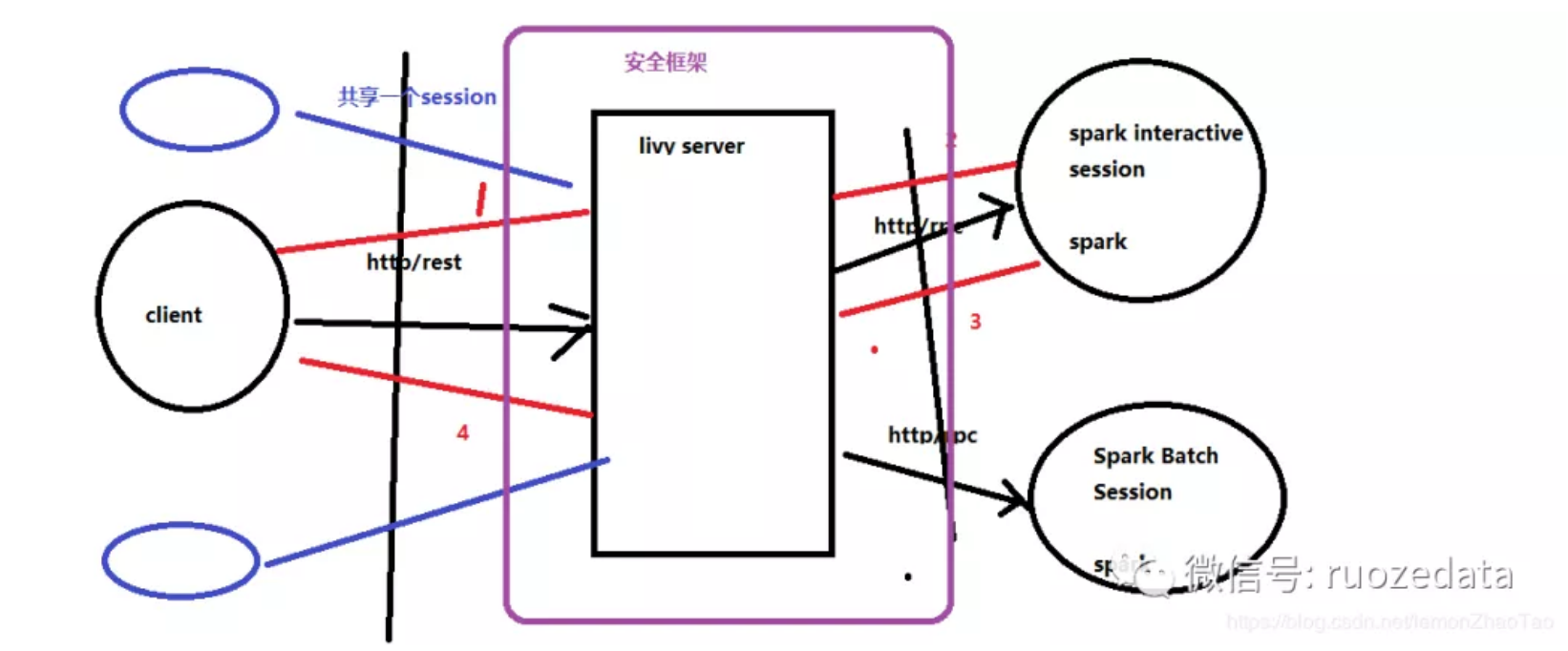
1、有个客户端client,中间有个livy server,后面有spark interactive session和spark batch session(在这2个里面的底层都是有一个SparkContext的)
2、client发请求过来(http或rest)到livy server,然后会去spark interactive session和spark batch session分别去创建2个session;与spark集群交互打交道,去创建session的方式有2种:http或rpc,现在用的比较多的方式是:rpc
3、livy server就是一个rest的服务,收到客户端的请求之后,与spark集群进行连接;客户端只需要把请求发到server上就可以了这样的话,就分为了3层:
- 最左边:其实就是一个客户单,只需要向livy server发送请求
- 到livy server之后就会去spark集群创建我们的session
- session创建好之后,客户端就可以把作业以代码片段的方式提交上来就OK了,其实就是以请求的方式发到server上就行
这样能带来一个优点,对于原来提交作业机器的压力可以减少很多,我们只要保障Livy Server的HA就OK了
对于这个是可以保证的
此架构与spark-submit的对比:使用spark-submit(yarn-client模式)必须在客户端进行提交,如果客户端那台机器挂掉了(driver跑在客户端上,因此driver也就挂了),那么作业全部都完成不了,这就存在一个单点问题
架构概况:
1 | 1、客户端发一个请求到livy server |
多用户的特性:
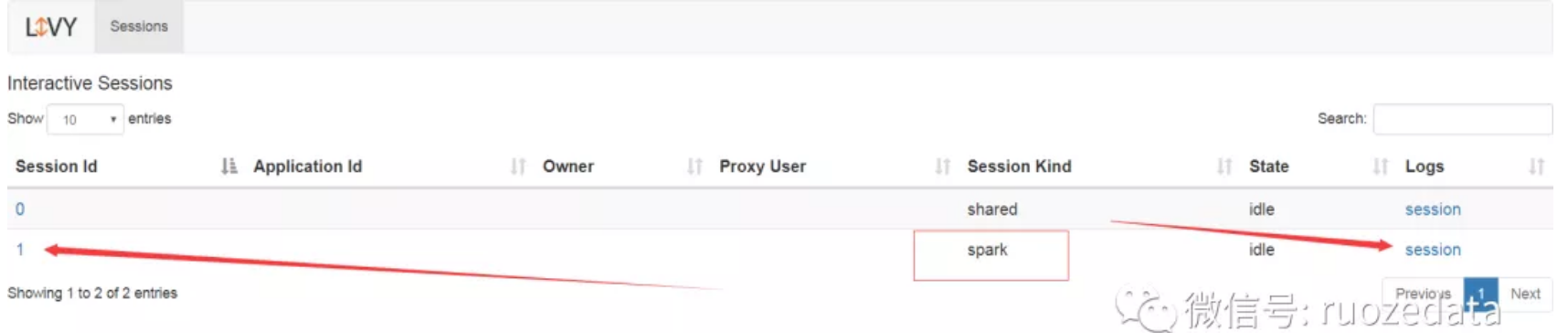
上述是一个用户的操作,如果第二个、第三个用户来,可以这样操作:
- 提交过去的时候,可以共享一个session
- 其实一个session就是一个SparkContext
比如:蓝色的client共享一个session,黑色的client共享一个session,可以通过一定的标识,它们自己能够识别出来
提交Spark作业案例
创建交互式的session
使用交互式会话的前提是需要先创建会话。当前的Livy可在同一会话中支持spark,pyspark或是sparkr三种不同的解释器类型以满足不同语言的需求。
1 | [hadoop@hadoop000 livy-0.5.0-incubating-bin]$ curl -X POST --data '{"kind":"spark"}' -H "Content-Type:application/json" hadoop000:8998/sessions |
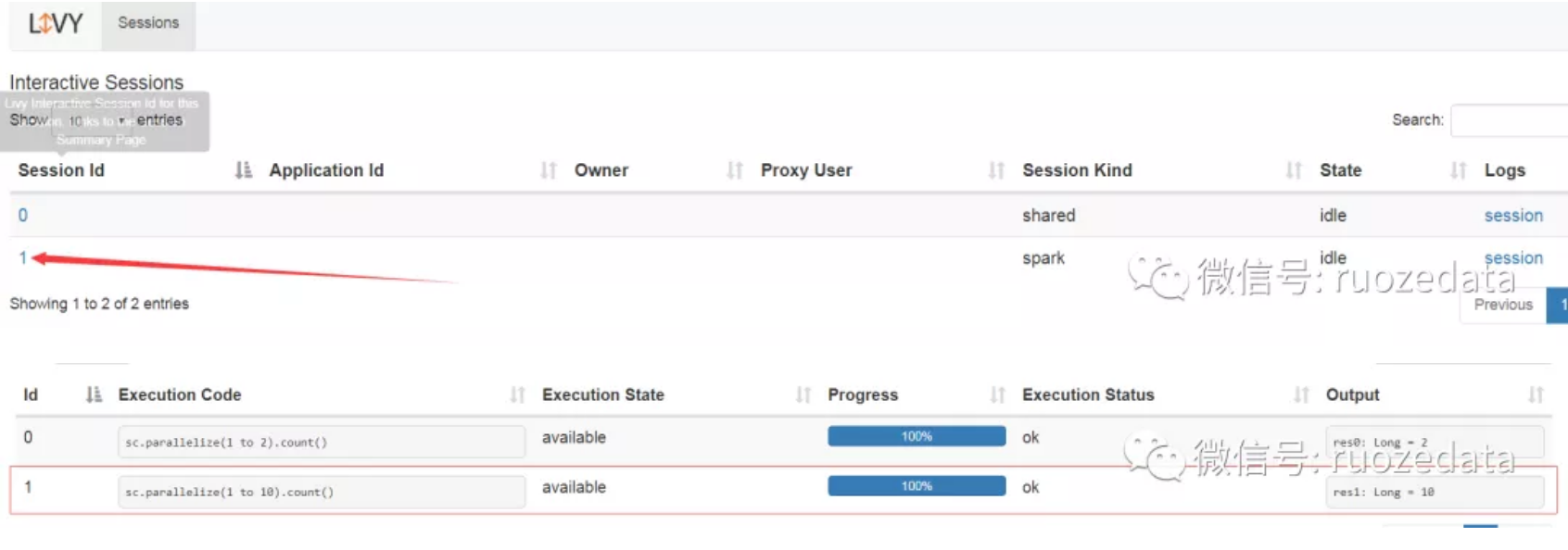
其中需要我们关注的是会话id,id代表了此会话,所有基于该会话的操作都需要指明其id
提交一个Spark的代码片段
sc.parallelize(1 to 10).count()
Livy的REST提交方式
1 | curl hadoop000:8998/sessions/1/statements -X POST -H 'Content-Type: application/json' -d '{"code":"sc.parallelize(1 to 2).count()", "kind": "spark"}' |
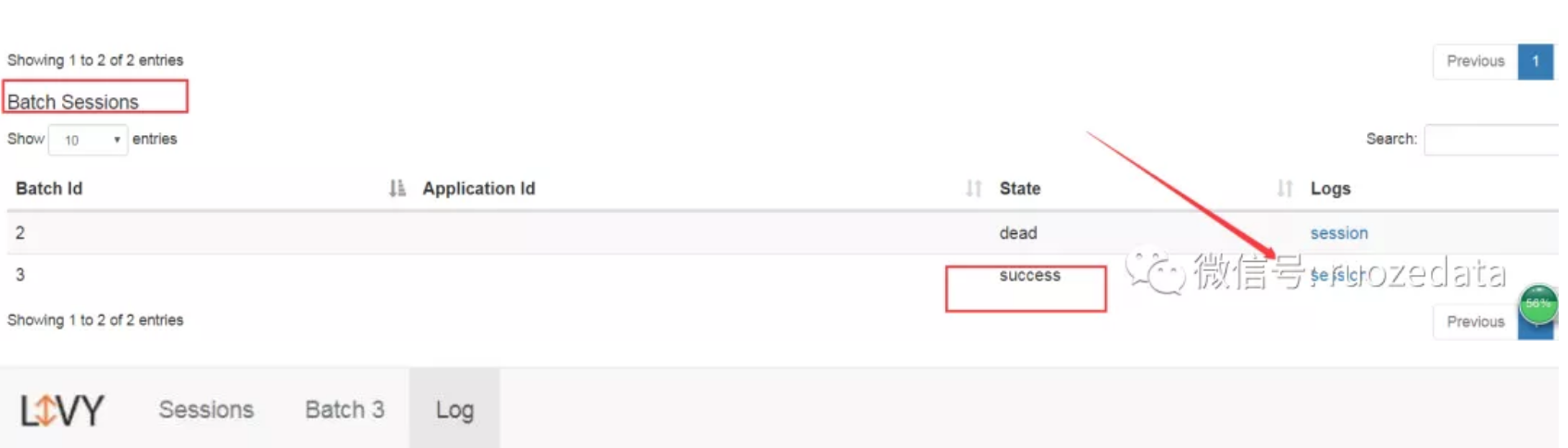
注意此代码片段提交到session_id为1的session里面去了,所以Web点击1
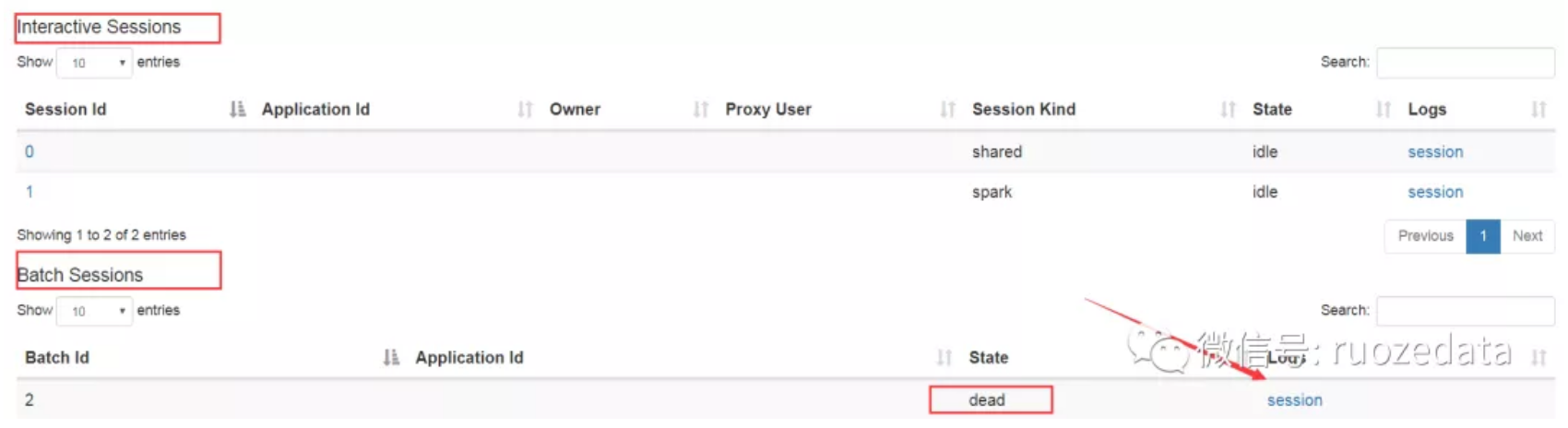
以批处理会话(Batch Session)提交打包的JAR
1 | package com.soul.bigdata.spark.core01 |
以上代码打包上传至
1 | [hadoop@hadoop000 lib]$ pwd |
使用Livy提交
curl -H “Content-Type: application/json” -X POST -d ‘{ “file”:”/home/hadoop/soul/libspark-train-1.0.jar”, “className”:”com.soul.bigdata.spark.core01.SparkWCApp” }’ hadoop000:8998/batches
查看Livy的Web界面报错
1 | 19/08/29 23:19:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable |
所以File后面跟的Path需要是HDFS路径,而不是本地路径,将打包的JAR上传至HDFS
1 | [hadoop@hadoop000 lib]$ hadoop fs -ls /lib |
再次提交
1 | curl -H "Content-Type: application/json" -X POST -d '{ "file":"/lib/spark-train-1.0.jar", "className":"com.soul.bigdata.spark.core01.SparkWCApp" }' hadoop000:8998/batches |
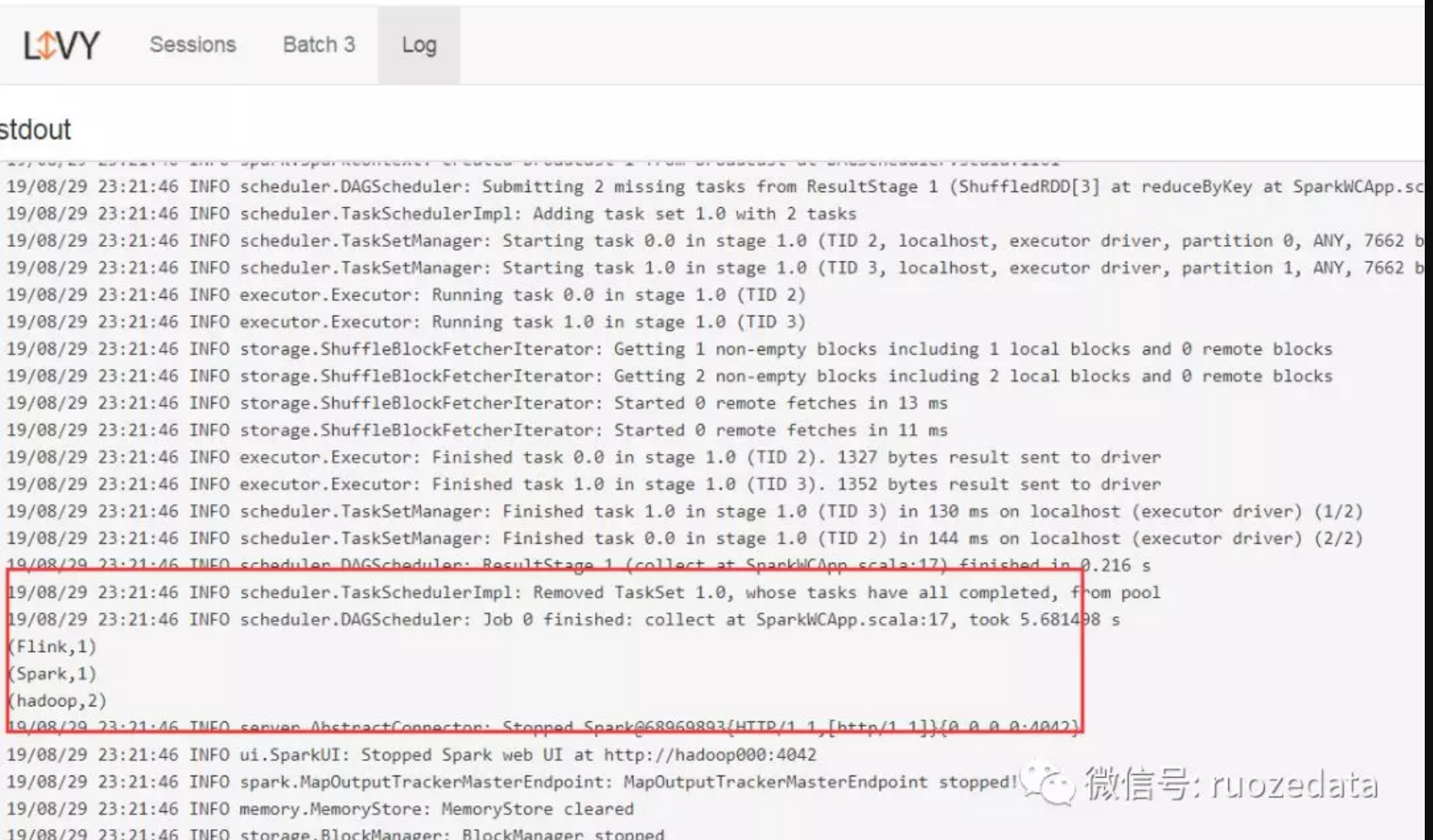
查看Web成功返回了我们需要的结果