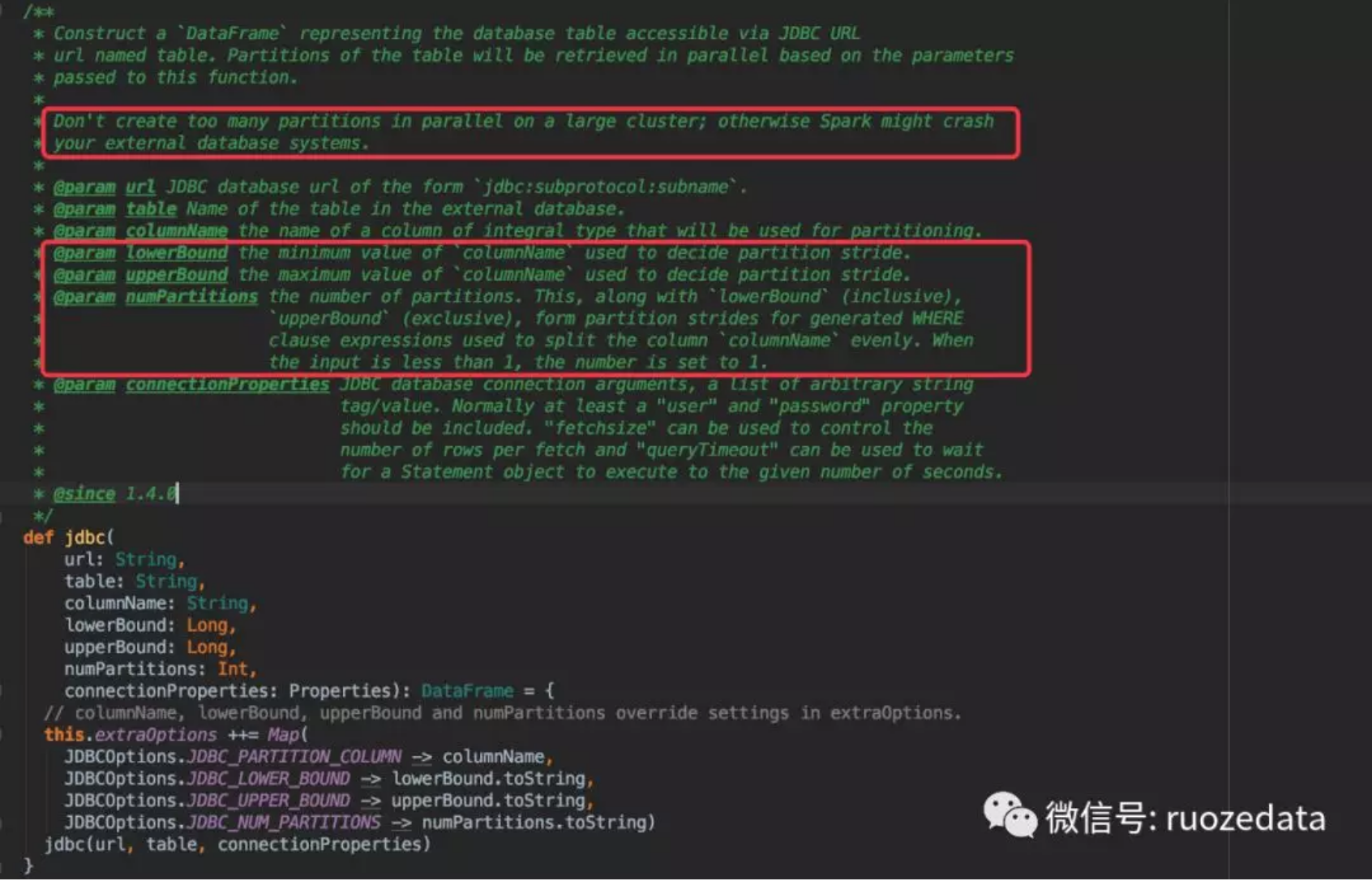
1.通过使用表字段数字类型的最大值和最小值加上numPartitions组合做相应的分区设置
背景:tableA的主键ID为Int类型,且属于以1为自增步长的自增键,那么对全表做数据加载方式如下
1 | val sql = "select * from tableA" // 查询tableA数据 |
其中此方法jdbc的源代码截图如下
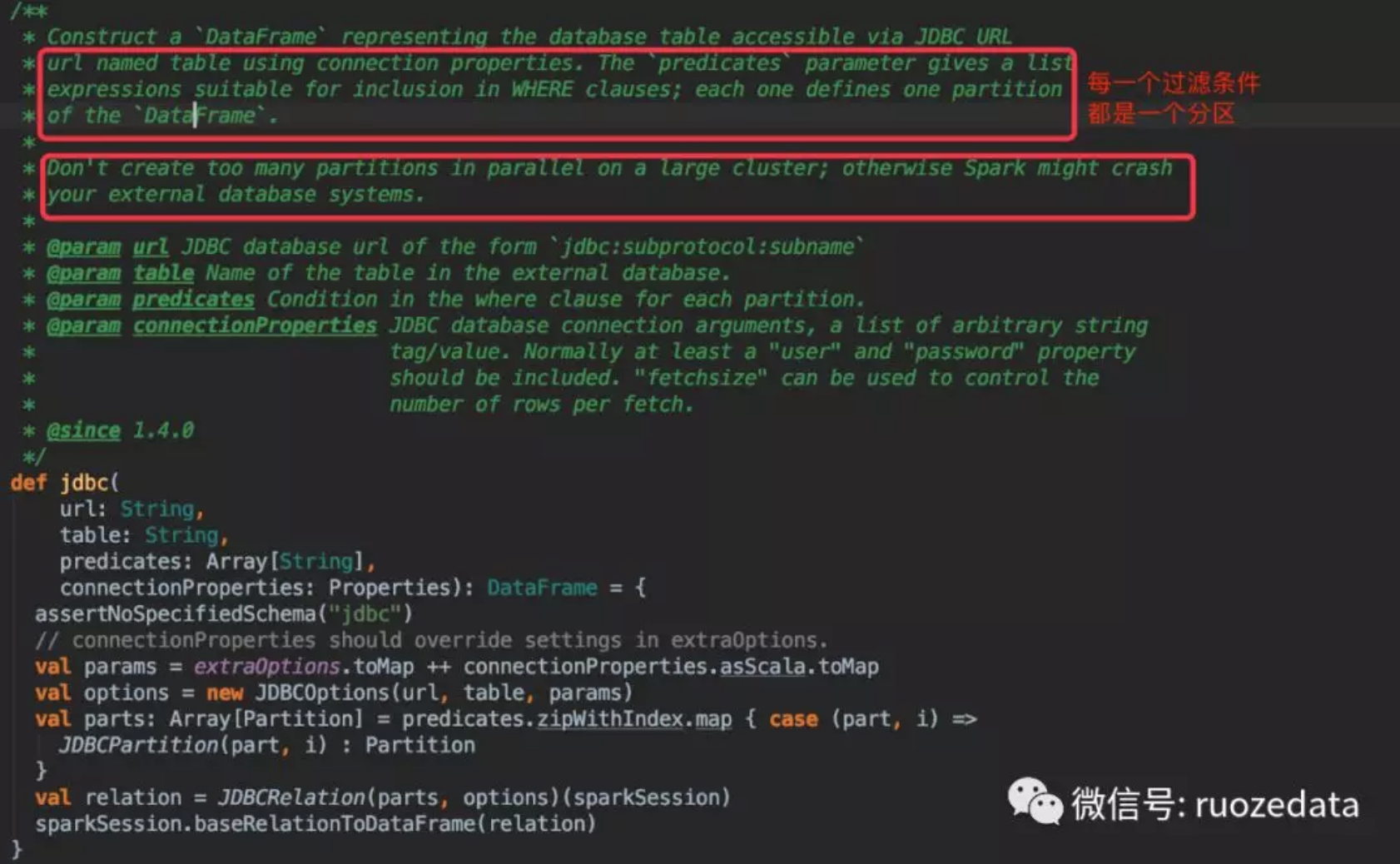
2.还有另外一种场景会出现主键ID并非数字类型,比如主键用的是UUID?上面的方式就不能使用了,但是又需要将数据相对均匀分布的放在N个partition内,此处可以使用第二种方式,按照不同条件做分区。
背景:tableA的表主键ID为UUID,有时间字段cretime,且此表数据属于均匀增长的业务表。
1 | /** 使用 创建时间字段 做分区 |
其中此方法jdbc的源代码截图如下
总结两点:
1.其中截图都有一块明确说明,分区的数量不要创建太多,否则很容易将你拉取的mysql数据库拉垮掉(重要)。
此处有两种操作方式:
1 | A)给作业的总core不要设置太大 |
方法,因为persist方法没有优化列选取,直接抓取的所有当前dataframe能拿到的列,这样对mysql是有压力的。
