学习路径
- 官网:http://impala.apache.org/
- 使用手册:http://impala.apache.org/docs/build/html/index.html
- Sql:http://impala.apache.org/docs/build/html/topics/impala_langref_sql.html
- 窗口函数:http://impala.apache.org/docs/build/html/topics/impala_functions.html
- 基本操作:http://impala.apache.org/docs/build/html/topics/impala_tutorial.html
- impala-shell:http://impala.apache.org/docs/build/html/topics/impala_impala_shell.html
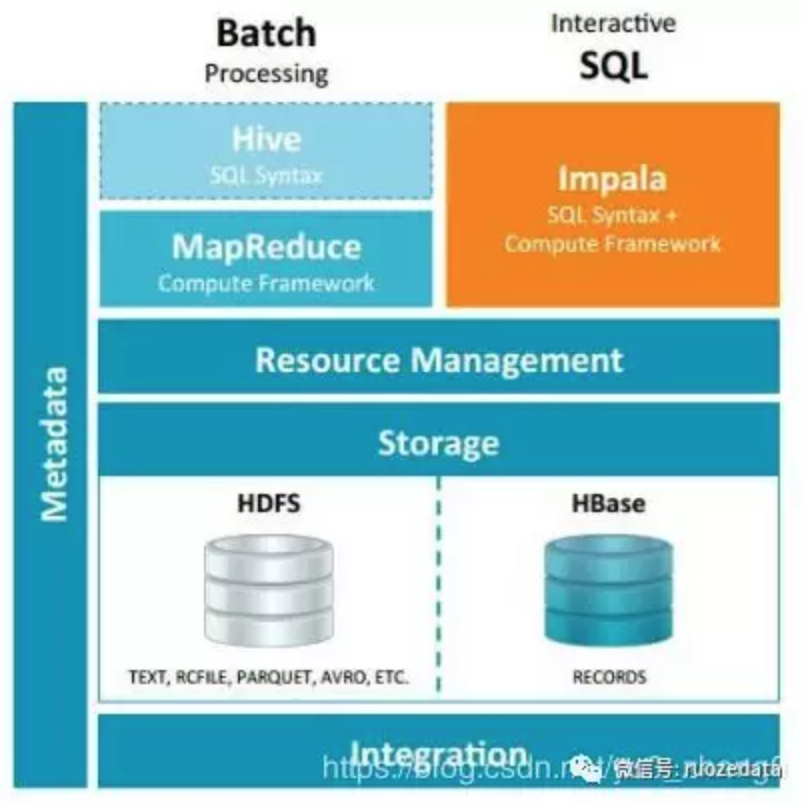
概述
- Apache Impala是Apache Hadoop的开源原生分析数据库;
- Impala于2017年11月15日从Apache孵化成顶级项目。在以前称为“Cloudera Impala”的文档中,现在的官方名称是“Apache Impala”。
- Impala为Hadoop上的BI /分析查询提供低延迟和高并发性(不是由Apache Hive等批处理框架提供)。即使在多租户环境中,Impala也可以线性扩展。
- 利用与Hadoop部署相同的文件和数据格式以及元数据,安全性和资源管理框架 - 无冗余基础架构或数据转换/复制。
- 对于Apache Hive用户,Impala使用相同的元数据和ODBC驱动程序。与Hive一样,Impala支持SQL
- Impala与本机Hadoop安全性和Kerberos集成以进行身份验证,通过Sentry模块,您可以确保为正确的用户和应用程序授权使用正确的数据。
- 使用Impala,无论是使用SQL查询还是BI应用程序,更多用户都可以通过单个存储库和元数据存储进行交互
什么是Impala
- Impala是一种面向实时或者面向批处理的框架;
- Impala的数据可以存储在HDFS,HBase和Amazon Simple Storage Servive(S3)中;
- Impala和Hive使用了相同的元数据存储;
- 可以通过SQL的语法,JDBC,ODBC和用户界面(Hue中的Impala进行查询);
我们知道Hive底层是MapReduce,在这里就可以看出区别了,Impala并不是为了替换构建在MapReduce上的批处理框架,就像我们说的Hive,Hive适用于长时间运行的批处理作业,例如涉及到Extract,Transform和Load(ETL)类型的作业.而Impala是进行实时处理的.
优势
- 通过sql进行大量数据处理;
- 可以进行分布式部署,进行分布式查询;
- 可以和不同组件之间进行数据共享,不需要复制或者导入,导出等步骤,例如:可以先使用hive对数据进行ETL操作然后使用Impala进行查询.因为Impala和hive公用同一个元数据,这样就可以方便的对hive生成的数据进行分析.
Impala如何与Apache Hadoop一起使用
Impala解决方案由以下组件组成:
- 客户端 - 包括Hue,ODBC客户端,JDBC客户端和Impala Shell的实体都可以与Impala进行交互。这些接口通常用于发出查询或完成管理任务,例如连接到Impala。
- Hive Metastore - 存储有关Impala可用数据的信息。例如,Metastore让Impala知道哪些数据库可用,以及这些数据库的结构是什么。在创建,删除和更改模式对象,将数据加载到表中等等时,通过Impala SQL语句,相关的元数据更改将通过Impala 1.2中引入的专用目录服务自动广播到所有Impala节点。
- Impala - 此过程在DataNodes上运行,协调并执行查询。Impala的每个实例都可以接收,计划和协调来自Impala客户端的查询。
HBase和HDFS -数据的存储。
下面这幅图应该说的很清楚了:
使用Impala执行的查询流程如下:
- 用户应用程序通过ODBC或JDBC向Impala发送SQL查询,这些查询提供标准化的查询接口。用户应用程序可以连接到impalad群集中的任何应用程序。这impalad将成为查询的协调者。
- Impala会解析查询并对其进行分析,以确定impalad整个群集中的实例需要执行哪些任务 。计划执行以实现最佳效率。
- 本地impalad实例访问HDFS和HBase等服务以提供数据。
- 每个都impalad将数据返回给协调impalad,协调将这些结果发送给客户端。
impala-shell
使用Impala shell工具(impala-shell)来设置数据库和表,插入数据和发出查询
| 选项 | 描述 |
|---|---|
| -B or –delimited | 导致使用分隔符分割的普通文本格式打印查询结果。当为其他 Hadoop 组件生成数据时有用。对于避免整齐打印所有输出的性能开销有用,特别是使用查询返回大量的结果集进行基准测试的时候。使用 –output_delimiter 选项指定分隔符。使用 -B 选项常用于保存所有查询结果到文件里而不是打印到屏幕上。在 Impala 1.0.1 中添加 |
| –print_header | 是否打印列名。整齐打印时是默认启用。同时使用 -B 选项时,在首行打印列名 |
| -o filename or –output_file filename | 保存所有查询结果到指定的文件。通常用于保存在命令行使用 -q 选项执行单个查询时的查询结果。对交互式会话同样生效;此时你只会看到获取了多少行数据,但看不到实际的数据集。当结合使用 -q 和 -o 选项时,会自动将错误信息输出到 /dev/null(To suppress these incidental messages when combining the -q and -o options, redirect stderr to /dev/null)。在 Impala 1.0.1 中添加 |
| –output_delimiter=character | 当使用 -B 选项以普通文件格式打印查询结果时,用于指定字段之间的分隔符(Specifies the character to use as a delimiter between fields when query results are printed in plain format by the -B option)。默认是制表符 tab (’\t’)。假如输出结果中包含了分隔符,该列会被引起且/或转义( If an output value contains the delimiter character, that field is quoted and/or escaped)。在 Impala 1.0.1 中添加 |
| -p or –show_profiles | 对 shell 中执行的每一个查询,显示其查询执行计划 (与 EXPLAIN 语句输出相同) 和发生低级故障(low-level breakdown)的执行步骤的更详细的信息 |
| -h or –help | 显示帮助信息 |
| -i hostname or –impalad=hostname | 指定连接运行 impalad 守护进程的主机。默认端口是 21000。你可以连接到集群中运行 impalad 的任意主机。假如你连接到 impalad 实例通过 –fe_port 标志使用了其他端口,则应当同时提供端口号,格式为 hostname:port |
| -q query or –query=query | 从命令行中传递一个查询或其他 shell 命令。执行完这一语句后 shell 会立即退出。限制为单条语句,可以是 SELECT, CREATE TABLE, SHOW TABLES, 或其他 impala-shell 认可的语句。因为无法传递 USE 语句再加上其他查询,对于 default 数据库之外的表,应在表名前加上数据库标识符(或者使用 -f 选项传递一个包含 USE 语句和其他查询的文件) |
| -f query_file or –query_file=query_file | 传递一个文件中的 SQL 查询。文件内容必须以分号分隔 |
| -k or –kerberos | 当连接到 impalad 时使用 Kerberos 认证。如果要连接的 impalad 实例不支持 Kerberos,将显示一个错误 |
| -s kerberos_service_name or –kerberos_service_name=name | Instructs impala-shell to authenticate to a particular impalad service principal. 如何没有设置 kerberos_service_name ,默认使用 impala。如何启用了本选项,而试图建立不支持Kerberos 的连接时,返回一个错误(If this option is used in conjunction with a connection in which Kerberos is not supported, errors are returned) |
| -V or –verbose | 启用详细输出 |
| –quiet | 关闭详细输出 |
| -v or –version | 显示版本信息 |
| -c | 查询执行失败时继续执行 |
| -r or –refresh_after_connect | 建立连接后刷新 Impala 元数据,与建立连接后执行 REFRESH 语句效果相同 |
| -d default_db or –database=default_db | 指定启动后使用的数据库,与建立连接后使用 USE 语句选择数据库作用相同,如果没有指定,那么使用 default 数据库 |
| -l | 启用 LDAP 认证 |
| -u | 当使用 -l 选项启用 LDAP 认证时,提供用户名(使用短用户名,而不是完整的 LDAP 专有名称(distinguished name)) ,shell 会提示输入密码 |
概念与架构
Impala Server的组件
Impala服务器是分布式,大规模并行处理(MPP)数据库引擎。它由在群集中的特定主机上运行的不同守护程序进程组成。
The Impala Daemon
Impala的核心组件是Impala daemon。Impala daemon执行的一些关键功能是:
- 读取和写入数据文件。
- 接受从impala-shell命令,Hue,JDBC或ODBC传输的查询。
- 并行化查询并在群集中分配工作。
- 将中间查询结果发送回中央协调器。
- 可以通过以下方式之一部署Impala守护程序:
- HDFS和Impala位于同一位置,每个Impala守护程序与DataNode在同一主机上运行。
- Impala单独部署在计算群集中,可从HDFS,S3,ADLS等远程读取。Impala守护进程与StateStore保持持续通信,以确认哪些守护进程是健康的并且可以接受新工作。
在Impala 2.9及更高版本中,您可以控制哪些主机充当查询协调器,哪些主机充当查询执行程序,以提高大型群集上高度并发工作负载的可伸缩性。
Impala Statestore
Impala Statestore进程检查集群中所有Impala daemon的运行状况,并把信息反馈给Impala daemon进程。您只需要在群集中的一台主机上执行此类过程。如果Impala守护程序由于硬件故障,网络错误,软件问题或其他原因而脱机,则StateStore会通知所有其他Impala daemon程序,以便将来的查询可以避免向无法访问的Impala守护程序发出请求。
因为StateStore的目的是在出现问题时提供帮助并向协调器广播元数据,因此对Impala集群的正常操作并不总是至关重要的。如果StateStore未运行或无法访问,则在处理Impala已知的数据时,Impala守护程序会像往常一样继续运行和分配工作。如果其他Impala守护程序失败,则群集变得不那么健壮,并且当StateStore脱机时,元数据变得不那么一致。当StateStore重新联机时,它会重新建立与Impala守护程序的通信并恢复其监视和广播功能。
The Impala Catalog Service
Impala Catalog Service进程可以把Impala SQL语句中的元数据更改信息反馈到集群中的所有Impala守护程序。只需要在群集中的一台主机上执行此类过程。因为请求是通过StateStore守护程序传递的,所以要在同一主机上运行statestored和catalogd服务。
当通过Impala发出的语句执行元数据更改时,Impala Catalog Service进程避免了REFRESH和INVALIDATE METADATA语句的使用,该进程可以为我们更新元数据信息。
使用–load_catalog_in_background选项控制何时加载表的元数据。
- 如果设置为false,则在第一次引用表时会加载表的元数据。这意味着第一次运行可能比后续运行慢。在impala2.2开始,默认load_catalog_in_background是 false。
- 如果设置为true,即使没有查询需要该元数据,目录服务也会尝试加载表的元数据。因此,当运行需要它的第一个查询时,可能已经加载了元数据。但是,由于以下原因,我们建议不要将选项设置为true。
后台加载可能会干扰查询特定的元数据加载。这可能在启动时或在使元数据无效之后发生,持续时间取决于元数据的数量,并且可能导致看似随机的长时间运行的查询难以诊断。
Impala可能会加载从未使用过的表的元数据,这会增加目录服务和Impala守护程序的目录大小,从而增加内存使用量。
负载均衡和高可用性的大多数注意事项适用于impalad守护程序。该statestored和catalogd守护进程不具备高可用性的特殊要求,因为这些守护进程的问题不会造成数据丢失。如果这些守护程序由于特定主机上的中断而变得不可用,则可以停止Impala服务,删除Impala StateStore和Impala目录服务器角色,在其他主机上添加角色,然后重新启动Impala服务。
数据类型
Impala支持一组数据类型,可用于表列,表达式值,函数参数和返回值。
注意: 目前,Impala仅支持标量类型,而不支持复合类型或嵌套类型。访问包含任何具有不受支持类型的列的表会导致错误。
有关Impala和Hive数据类型之间的差异,请参阅:
http://impala.apache.org/docs/build/html/topics/impala_langref_unsupported.html#langref_hiveql_delta
- ARRAY复杂类型(仅限Impala 2.3或更高版本)
- BIGINT数据类型
- BOOLEAN数据类型
- CHAR数据类型(仅限Impala 2.0或更高版本)
- DECIMAL数据类型(仅限Impala 3.0或更高版本)
- 双数据类型
- FLOAT数据类型
- INT数据类型
- MAP复杂类型(仅限Impala 2.3或更高版本)
- REAL数据类型
- SMALLINT数据类型
- STRING数据类型
- STRUCT复杂类型(仅限Impala 2.3或更高版本)
- TIMESTAMP数据类型
- TINYINT数据类型
- VARCHAR数据类型(仅限Impala 2.0或更高版本)
- 复杂类型(仅限Impala 2.3或更高版本)
