- Driver端初始化构建Accumulator并初始化,同时完成了Accumulator注册,Accumulators.register(this)时Accumulator会在序列化后发送到Executor端
- Driver接收到ResultTask完成的状态更新后,会去更新Value的值 然后在Action操作执行后就可以获取到Accumulator的值了
- Executor端接收到Task之后会进行反序列化操作,反序列化得到RDD和function。同时在反序列化的同时也去反序列化Accumulator(在readObject方法中完成),同时也会向TaskContext完成注册
- 完成任务计算之后,随着Task结果一起返回给Driver
结合源码分析
Driver端初始化Driver端主要经过以下步骤,完成初始化操作:
1 | val accum = sparkContext.accumulator(0, “AccumulatorTest”) |
反序列化是在调用ResultTask的runTask方式时候做的操作:
1 | // 会反序列化出来RDD和自己定义的function |
在反序列化的过程中,会调用Accumulable中的readObject方法:
1 | private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException { |
Accumulable.scala中的value_,是不会被序列化的,@transient关键词修饰了
1 | @volatile @transient private var value_ : R = initialValue // Current value on master |
累加器在各个节点的累加操作
针对传入function中不同的操作,对应有不同的调用方法,以下列举几种(在Accumulator.scala中):
1 | def += (term: T) { value_ = param.addAccumulator(value_, term) } |
根据不同的累加器参数,有不同实现的AccumulableParam(在Accumulator.scala中):
1 | trait AccumulableParam[R, T] extends Serializable { |
不同的实现如下图所示:
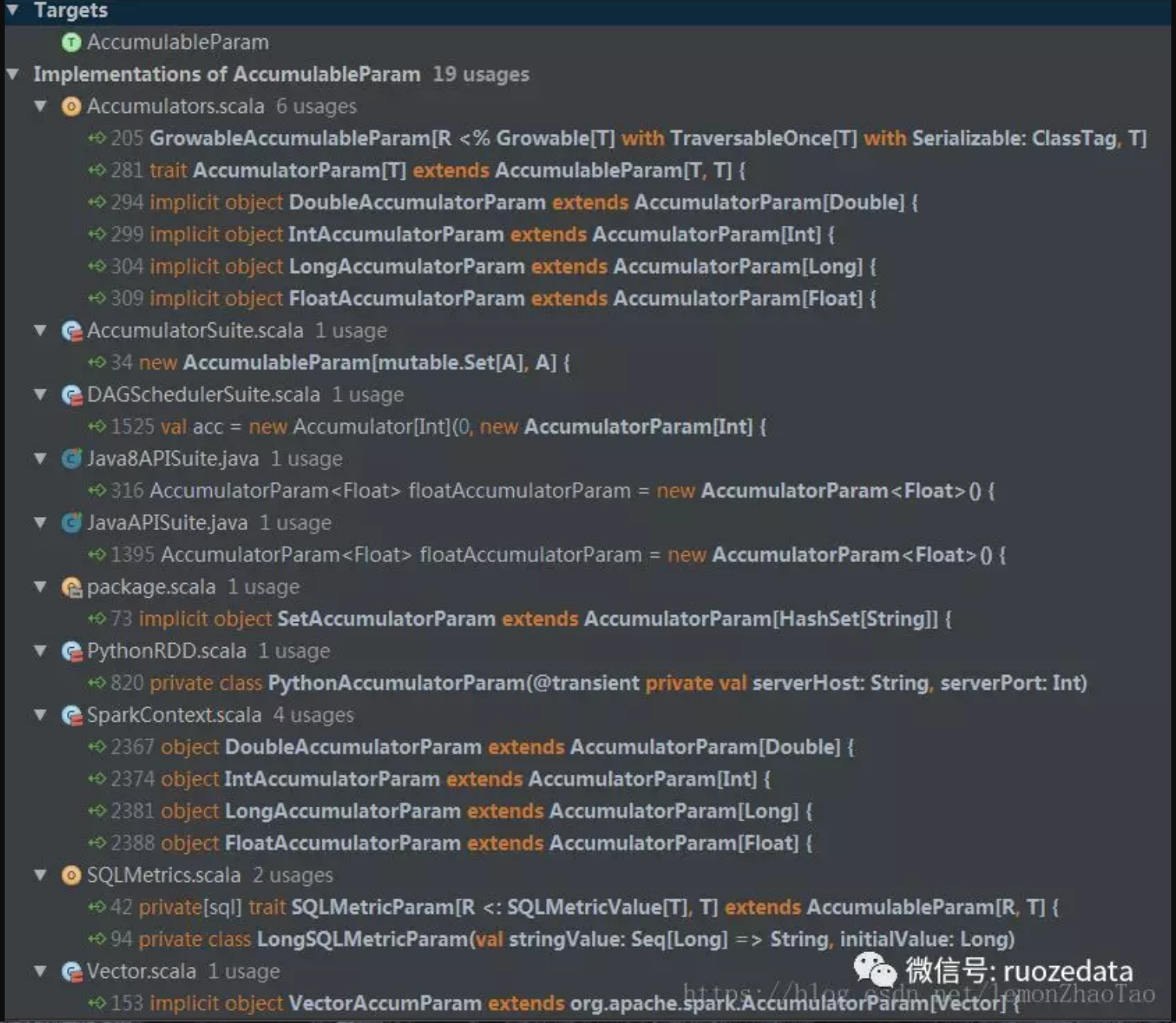
以IntAccumulatorParam为例:
1 | implicit object IntAccumulatorParam extends AccumulatorParam[Int] { |
我们发现IntAccumulatorParam实现的是trait AccumulatorParam[T]:
1 | trait AccumulatorParam[T] extends AccumulableParam[T, T] { |
在各个节点上的累加操作完成之后,就会紧跟着返回更新之后的Accumulators的value_值
聚合操作
在Task.scala中的run方法,会执行如下:
1 | // 返回累加器,并运行task |
在Executor端已经完成了一系列操作,需要将它们的值返回到Driver端进行聚合汇总,整个顺序如图累加器执行流程:
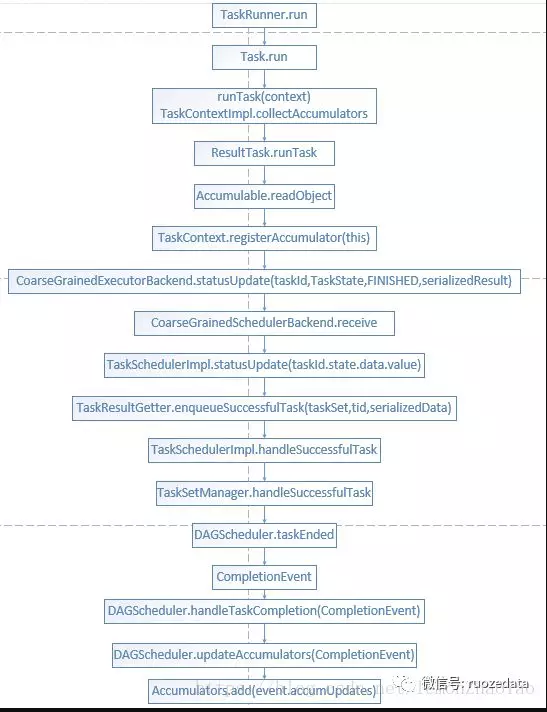
根据执行流程,我们可以发现,在执行完collectAccumulators方法之后,最终会在DAGScheduler中调用updateAccumulators(event),而在该方法中会调用Accumulators的add方法,从而完成聚合操作:
1 | def add(values: Map[Long, Any]): Unit = synchronized { |
获取累加器的值
通过accum.value方法可以获取到累加器的值
至此,累加器执行完毕。