步骤:
- 安装部署单机Kafka
- 创建MySQL表
- SparkStreaming实时消费
安装Kafka
注:出于方便以及机器问题,使用单机部署,并不需要另外安装zookeeper,使用kafka自带的zookeeper。
- 下载https://kafka.apache.org/downloads(使用版本:kafka_2.11-0.10.0.1.tgz)
编辑
server.properties文件1
2
3host.name=内网地址 # kafka绑定的interface
advertised.listeners=PLAINTEXT://外网映射地址:9092 # 注册到zookeeper的地址和端口#添加如上两个地址(云主机!)
log.dirs=/opt/software/kafka/logs #配置log日志地址bin/zookeeper-server-start.sh ../config/zookeeper.properties
如果使用bin/zookeeper-server-start.sh config/zookeeper.properties会导致无法找到config目录而报错。所以最好将kafka配置到全局环境变量中
使用
nohup /zookeeper-server-start.sh ../config/zookeeper.properties &启动后台服务bin/kafka-server-start.sh ../config/server.properties
可以用使用
nohup kafka-server-start.sh config/server.properties &启动后台服务bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test #创建topic
- bin/kafka-topics.sh –list –zookeeper localhost:2181 测试是否创建成功
- 启动生产者:bin/kafka-console-producer.sh –broker-list localhost/或者云主机外网ip:9092 –topic test
安装MySQL
使用yum安装mysql5.6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34安装:
cat >/etc/yum.repos.d/MySQL5.6.repo<<EOF
# Enable to use MySQL 5.6
[mysql56-community]
name=MySQL 5.6 Community Server
baseurl=http://repo.mysql.com/yum/mysql-5.6-community/el/6/\$basearch/
enabled=1
gpgcheck=0
EOF
yum -y install mysql-community-server
# 使用已经下载好的rpm包安装:
# yum -y localinstall \
# mysql-community-common-5.6.39-2.el6.x86_64.rpm \
# mysql-community-client-5.6.39-2.el6.x86_64.rpm \
# mysql-community-libs-compat-5.6.39-2.el6.x86_64.rpm \
# mysql-community-libs-5.6.39-2.el6.x86_64.rpm \
# mysql-community-server-5.6.39-2.el6.x86_64.rpm
chkconfig mysqld on
/etc/init.d/mysqld start
启动:
mysqladmin -u root password root
mysql -uroot -proot
use mysql;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' IDENTIFIED BY 'root' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'127.0.0.1' IDENTIFIED BY 'root' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
update user set password=password('root') where user='root';
delete from user where not (user='root') ;
delete from user where user='root' and password='';
drop database test;
DROP USER ''@'%';
flush privileges;
exit;创建测试表
1
2
3
4create database ruozedata;
use ruozedata;
grant all privileges on ruozedata.* to ruoze@'%' identified by '123456';
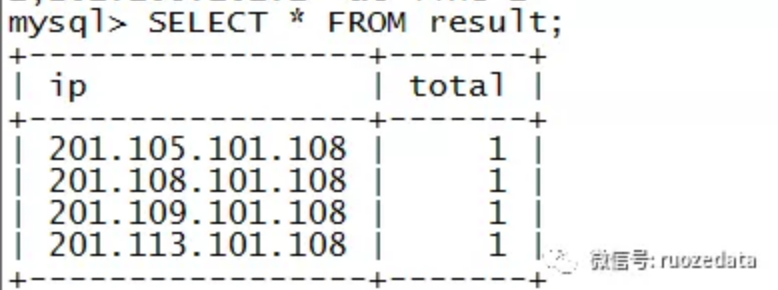
CREATE TABLE `test` ( `ip` varchar(255) NOT NULL, `total` int(11) NOT NULL, PRIMARY KEY (`ip`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
KafkaAndSparkStreamingToMySQL
1 | package com.ruozedata.G5 |
POM文件
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" |