我们不做过多宣传,因为我们是若泽数据,企业在职。
(现在其他机构也效仿我们说,企业在职,哎,很无语了)
直接看学员offer及刚出炉的面试题,难吗?
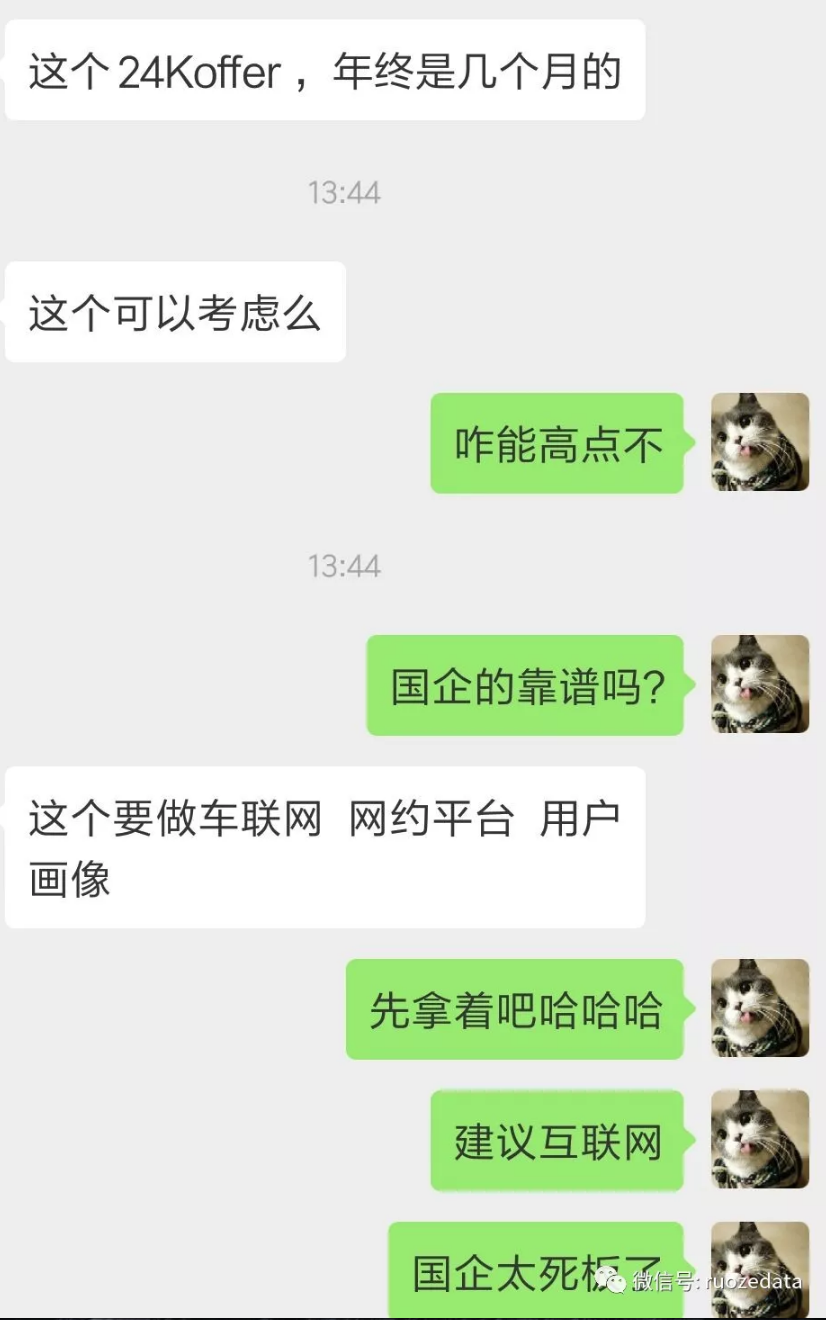
1.先看第一个高级班小伙伴,月薪24K,没有明确年终奖几个月。
- 数据源有哪些?指标是什么
- 在做项目时,约定和配置你们是怎么选的
- datax到数据到hdfs
- datax的并发条件
- 使用linux查看hive的表
- hive命令查看内部表外部表
- kafka的分区
- hbase批量写数据出现行级事务锁
- linux查看文件的前10行
- sqoop的并发操作以及并发条件
- 对于hadoop节点如何动态上下线
- 分组求和:用mapreduce实现
- kafka redis怎么选型 用在什么场景
- hive 表结构经常变化 怎么处理(除了外部表 有什么其他解决方案)
- mongodb即作为元数据信息和规则信息,还存储一些图片文章,马上mongodb出现了瓶颈了,如何解决
- 集群一台 dstanode挂了怎么复制的
- kafka 不丢数据怎么做
- spark-streaming数据倾斜的两种原因,以及解决办法
- mysql的单例和联合索引
- mysql数据库备份方式
- 设计一个责任链
- scala和java的区别
- 反射在spark中的应用
- 反射在hadoop中的应用
- 反射和泛型
- sql中的left join 和 join区别
- 在a.sh中执行b.sh
- hive的数据倾斜怎么解决
- 文件大小1G,每一行就是一个单词,求频率最高的单词的top100 , 要求只用1M内存
- spark和sparkStraming中的常用代码
- hive的新用户和老用户查询登录的问题
- 使用hive求日留存和pvuv
- 使用hive求连续登陆的用户
- Kafka原理
- hive的外部表与内部表区别
- hive的分区和分桶的区别
- hive的索引
- hdfs的ha中,zookeeper所起到的作用
- 监控,服务发现
- zookeeper平时有哪些作用
- mr的shuffle和spark的shuffle的区别
- flink和sparkStreaming的区别
- 机架感知(上传文件后是怎么存储的)
- hdfs的写数据流程
- spark2.0新特性
- 实现sparkStreaming的HA
- checkpoint的缺陷
