我们不做过多宣传,因为我们是若泽数据,企业在职。
(现在其他机构也效仿我们说,企业在职,哎,很无语了)
直接看学员offer及刚出炉的面试题,难吗?
1.上海小伙伴拿了月薪25K的offer(其实手里有3个offer)

- 自我介绍
讲一下实时数仓那个项目
- 架构设计,节点数量,进程内存分配
- Kafka的多次消费及消费紊乱,你们怎么保证的
- 你们每天的数据量多少
- 你们的rowkey怎么设计的避免热点问题
之后 围绕笔试题
- Spark ReduceByKey 和 GroupByKey什么区别 会不会有shuffle
- 宽窄依赖区别
- left join 以及 inner join 以及 笛卡尔积什么区别
- 笔试题第一题里面的聚合怎么做(考了个outer full join
- 聚集索引 和 非聚集索引什么区别
- Spark的map 与 mappatition区别
- 什么情况下使用广播变量 数据量大 还是 数据量小 为什么
- Spark累加器你们是怎么用的
- SQL优化说说怎么做的
- like在什么情况下索引不会命中
- 如果第一题用shell做,会吗(考验awk 和 sed)
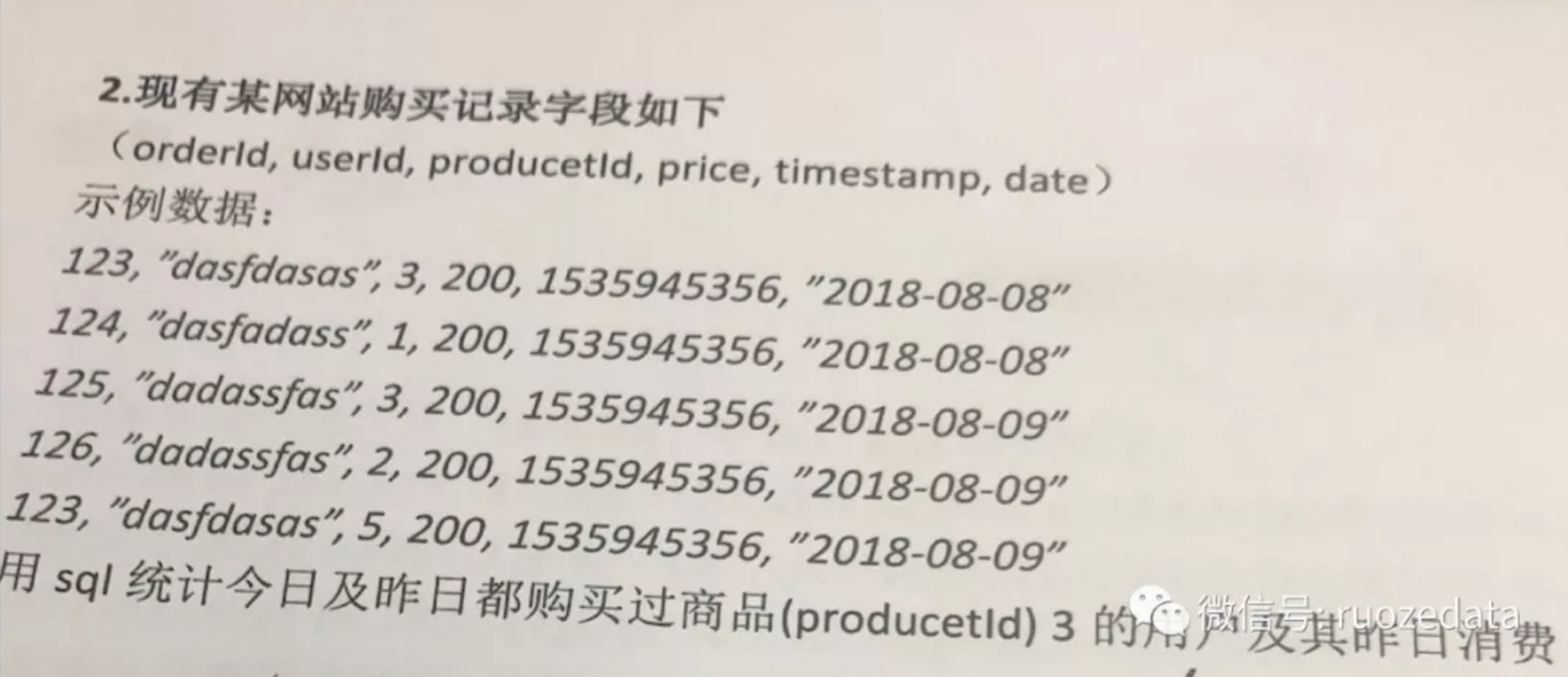
- 笔试题: