若泽数据,创办三年来,高级班课表已经更新V3版本,和老师的企业生产项目同步更新!官网课表已经更新!
本次课程以6大生产项目为驱动:
- 生产上怎么开发、怎么debug源代码、怎么调优、怎么故障排查;
- 高级班就怎么教学,让我们实实在在学习真的大数据技术;
- 不套路,不搞pv、uv、demo级别、不读PPT;
- 全程官网(更新最快)学习、剖析、跟踪、教会大家怎样去学习。
其实有个同学有句话说的很好,
若泽数据的培训,更像是企业的老同事带领新同事,进行开发战斗! 接下来看2个刚出炉的offer,高吗?高吗?高吗? 1.高级班第5期–某北京学员,课程才学完60%,年薪32W。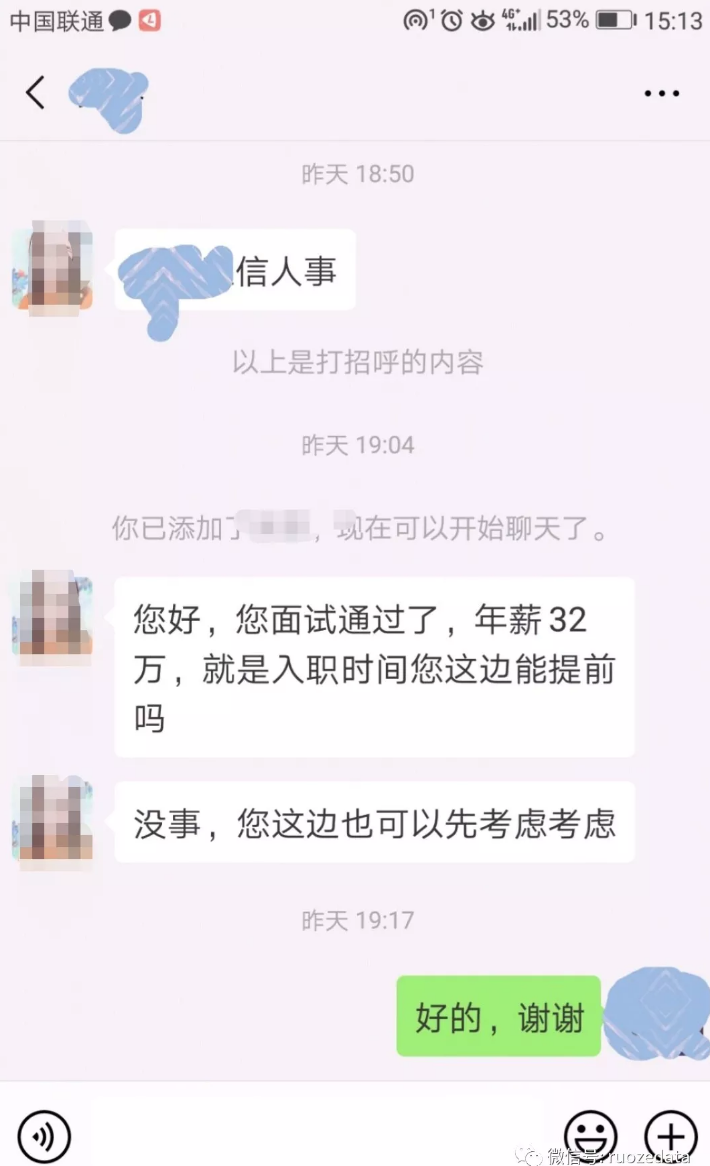
来看看面试题:
- hive1.x和hive2.x的区别?
- yarn如何做资源隔离?
- Spark作业上线流程?
- MySQL事务隔离级别
- MySQL调优流程?
- Oracle逻辑读大能调整吗?
- Spark作业上线资源评估
- 讲述一下你在项目中做了哪些东西?
- 每天处理的数据量
- 会产生小文件吗?小文件在项目的那个环节处理?
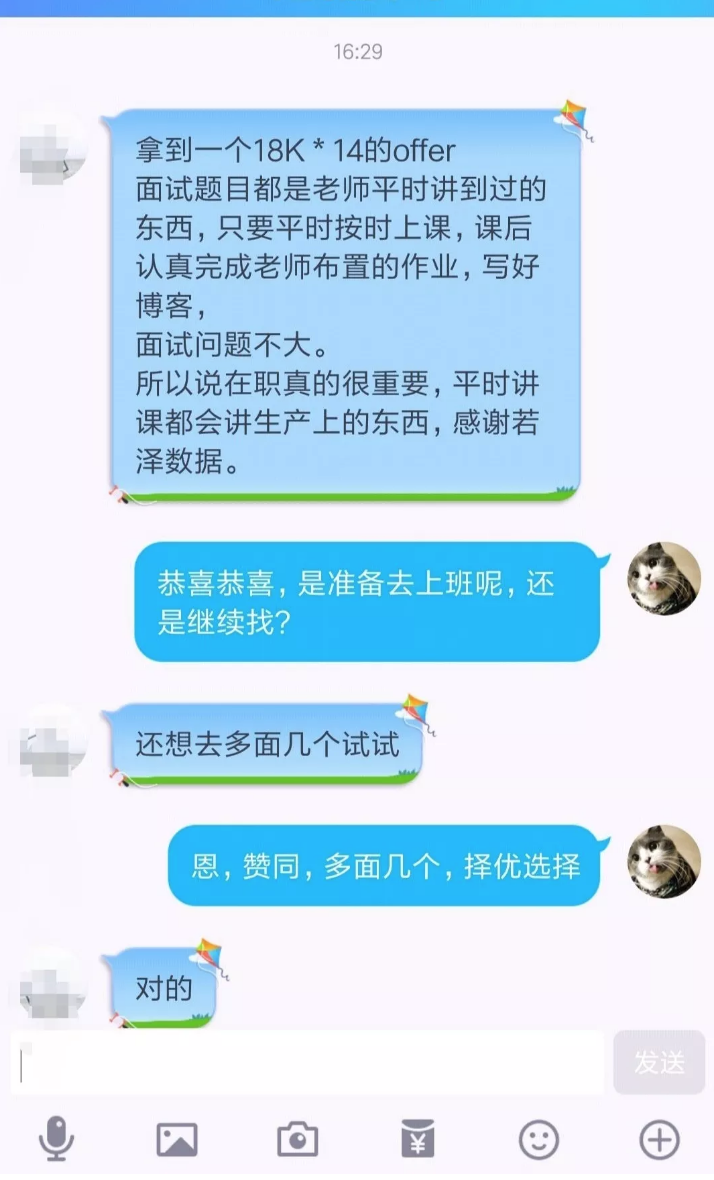
来看看面试题:
- 数据倾斜
- Spark应用中遇到的问题(说了OOM和序列化问题)
- hbase解决数据热点
- hbase region如何切分?做预切分吗?
- Spark on yarn
- 小文件问题(他们做的是每天归档)
- SparkStreaming和Kafka对接时,kafka的分区和SparkStreaming分区是怎么对应的
- 工作中用第三方工具来监控kafka吗
- 会kafka调优吗
- 会Spark调优吗?工作中调优了哪些参数
- Spark宽依赖和窄依赖
- hive底层存储格式
- 了不了解flink,它和spark的区别在哪里
- yarn资源队列
