一、Spark在携程应用的现状
集群规模:
平均每天MR任务数:30W+
开发平台:
调度系统运行的任务数:10W+
每天运行任务实例数:23W+
ETL/计算任务:~58%
查询平台:
adhoc查询:2W+
支持Spark/Hive/Presto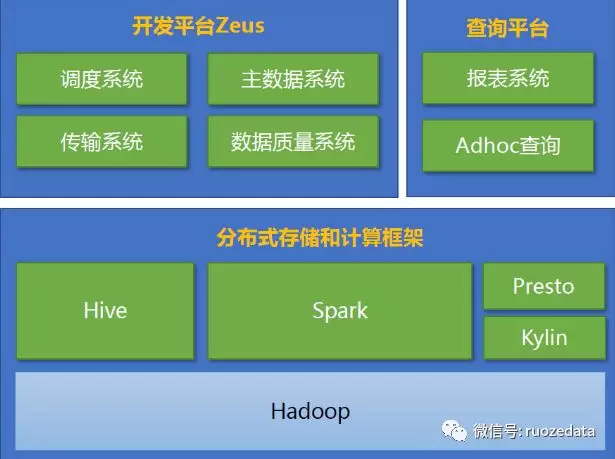
二、Hive与Spark的区别
Hive:
优点:运行稳定,客户端内存消耗小。
存在问题:生成多个MapReduce作业;中间结果落地,IO开销大;频繁申请和释放container,资源没有合理充分利用
Spark:
快:高效的DAG执行引擎,可以基于内存来高效的处理数据流,节省大量IO开销
通用性:SparkSQL能直接使用HiveQL语法,Hive Metastore,Serdes,UDFs
三、迁移SparkSQL的挑战
兼容性:
Hive原先的权限控制
SQL语法,UDF和Hive的兼容性
稳定性:
迁移透明,低优先级用户无感知
监控作业迁移后成功率及运行时长对比
准确性:
数据一致
功能增强:
用户体验,是否易用,报错信息是否可读
潜在Bug
周边系统配合改造
血缘收集
四、兼容性改造
移植hive权限
Spark没有权限认证模块,可对任意表进行查询,有安全隐患
需要与Hive共享同一套权限
方案:
执行SQL时,对SQL解析得到LogicalPlan,对LogicalPlan进行遍历,提取读取的表及写入的表,调用Hvie的认证方法进行检查,如果有权限则继续执行,否则拒绝该用户的操作。
SQL语法和hive兼容
Spark创建的某些视图,在Hive查询时报错,Spark创建的视图不会对SQL进行展开,视图定义没有当前的DB信息,Hive不兼容读取这样的视图
方案:、
保持与Hive一致,在Spark创建和修改视图时,使用hive cli driver去执行create/alter view sql
UDF与hive兼容
UDF计算结果不一样,即使是正常数据,Spark返回null,Hive结果正确;异常数据,Spark抛exception导致作业失败,Hive返回的null。
方案:
Spark函数修复,比如round函数
将hive一些函数移植,并注册成永久函数
整理Spark和Hive语法和UDF差异
五、稳定性和准确性
稳定性:
迁移透明:调度系统对低优先级作业,按作业粒度切换成Spark执行,失败后再切换成hive
灰度变更,多种变更规则:支持多版本Spark,自动切换引擎,Spark v2 -> Spark v1 -> Hive;灰度推送参数,调优参数,某些功能
监控:每日统计spark和hive运行对比,每时收集作业粒度失败的Spark作业,分析失败原因
准确性:
数据质量系统:校验任务,检查数据准确性
六、功能增强
Spark Thrift Server:
- 1.基于delegation token的impersontion
Driver:
为不同的用户拿delegation token,写到staging目录,记录User->SQL->Job映射关系,分发task带上对应的username
Executor:
根据task信息带的username找到staging目录下的token,加到当前proxy user的ugi,实现impersonate - 2.基于zookeeper的服务发现,支持多台server
这一块主要移植了Hive zookeeper的实现 - 3.限制大查询作业,防止driver OOM
限制每个job产生的task最大数量
限制查询SQL的最大行数,客户端查询大批量数据,数据挤压在Thrift Server,堆内内存飙升,强制在只有查的SQL加上limit
限制查询SQL的结果集数据大小 - 4.监控
对每个server定时查询,检测是否可用
多运行时长较久的作业,主动kill用户体验
用户看到的是类似Hive MR进度的日志,INFO级别日志收集到ES,可供日志的分析和排查问题
收集生成的表或者分区的numRows numFile totalSize,输出到日志
对简单的语句,如DDL语句,自动使用–master=local方式启动Combine input Format
在HadoopTableReader#makeRDDForTable,拿到对应table的InputFormatClass,转换成对应格式的CombineInputFormat
通过开关来决定是否启用这个特性
set spark.sql.combine.input.splits.enable=true
通过参数来调整每个split的total input size
mapreduce.input.fileinputformat.split.maxsize=256MB 10241024
之前driver读大表高峰时段split需要30分钟不止,才把任务提交上,现在只要几分钟就算好split的数量并提交任务,也解决了一些表不大,小文件多,能合并到同一个task进行读取
