版本:
spark 2.2.0
hive 1.1.0
scala 2.11.8
hadoop-2.6.0-cdh5.7.0
jdk 1.8
MongoDB 3.6.4
一 原始数据及Hive表
MongoDB数据格式
1 | { |
Hive普通表
1 | create table mg_hive_test( |
Hive分区表
1 | create table mg_hive_external( |
二 IDEA+Maven+Java
依赖
1 | <dependency> |
代码
1 | package com.huawei.mongo;/* |
工具类
1 | package com.huawei.mongo;/* |
三 错误解决办法
1 IDEA会获取不到Hive的数据库和表,将hive-site.xml放入resources文件中。并且将resources设置成配置文件(设置成功文件夹是蓝色否则是灰色)
file–>Project Structure–>Modules–>Source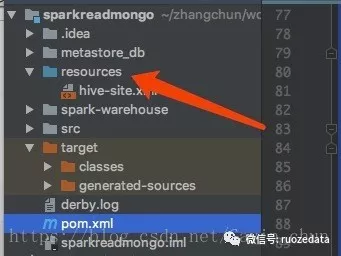
2 上面错误处理完后如果报JDO类型的错误,那么检查HIVE_HOME/lib下时候否mysql驱动,如果确定有,那么就是IDEA获取不到。解决方法如下:
将mysql驱动拷贝到jdk1.8.0_171.jdk/Contents/Home/jre/lib/ext路径下(jdk/jre/lib/ext)
在IDEA项目External Libraries下的<1.8>里面添加mysql驱动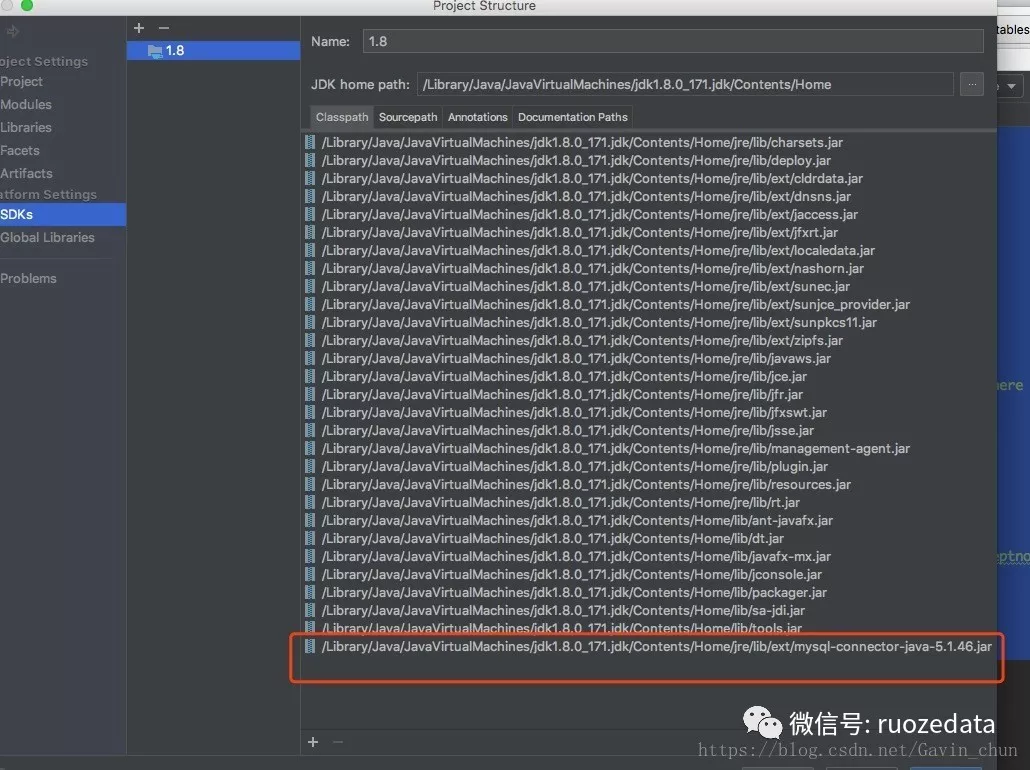
四 注意点
由于将MongoDB数据表注册成了临时表和Hive表进行了关联,所以要将MongoDB中的id字段设置成索引字段,否则性能会很慢。
MongoDB设置索引方法:
1 | db.getCollection('mgtest').ensureIndex({"id" : "1"}),{"background":true} |
查看索引:
1 | db.getCollection('mgtest').getIndexes() |
