1.下载Flink安装包
flink下载地址
https://archive.apache.org/dist/flink/flink-1.5.0/
因为例子不需要hadoop,下载flink-1.5.0-bin-scala_2.11.tgz即可
2.解压
tar -zxf flink-1.5.0-bin-scala_2.11.tgz -C ../opt/
3.配置master节点
选择一个 master节点(JobManager)然后在conf/flink-conf.yaml中设置jobmanager.rpc.address 配置项为该节点的IP 或者主机名。确保所有节点有有一样的jobmanager.rpc.address 配置。
jobmanager.rpc.address: node1
(配置端口如果被占用也要改 如默认8080已经被spark占用,改成了8088)
rest.port: 8088
本次安装 master节点为node1,因为单机,slave节点也为node1
4.配置slaves
将所有的 worker 节点 (TaskManager)的IP 或者主机名(一行一个)填入conf/slaves 文件中。
5.启动flink集群
bin/start-cluster.sh
打开 http://node1:8088 查看web页面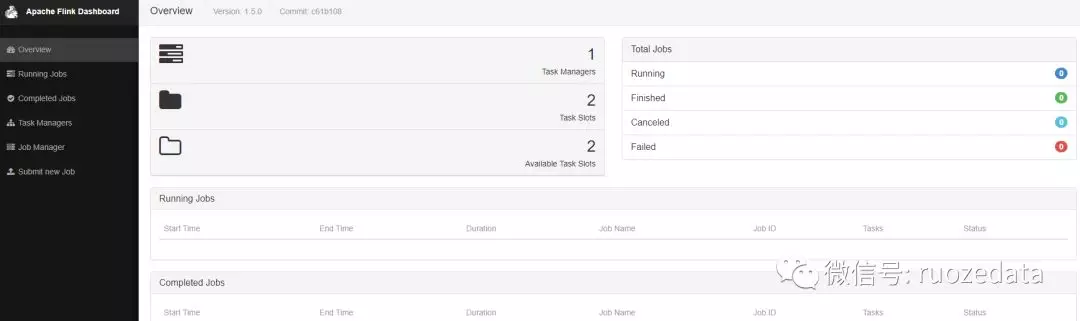
Task Managers代表当前的flink只有一个节点,每个task还有两个slots
6.测试
依赖
1 | <groupId>com.rz.flinkdemo</groupId> |
7.Socket测试代码
1 | public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // the port to connect to |
打包mvn clean install (如果打包过程中报错java.lang.OutOfMemoryError)
在命令行set MAVEN_OPTS= -Xms128m -Xmx512m
继续执行mvn clean install
生成FlinkTest.jar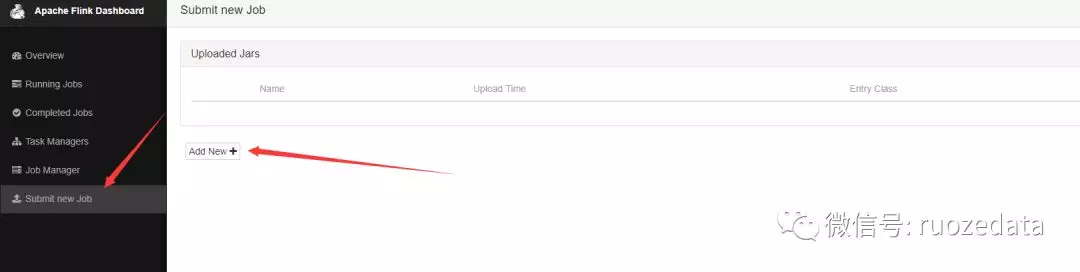
找到打成的jar,并upload,开始上传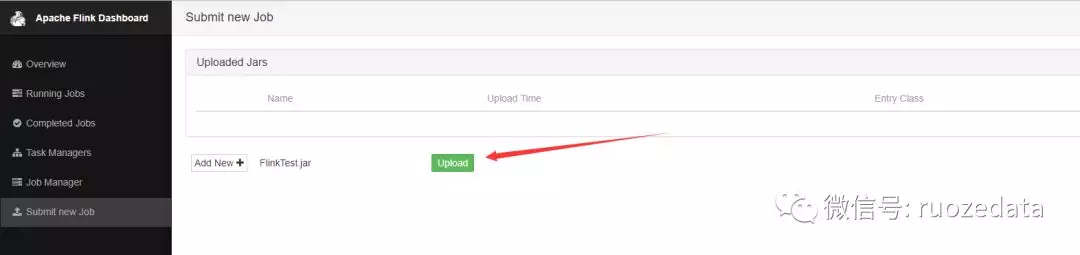
运行参数介绍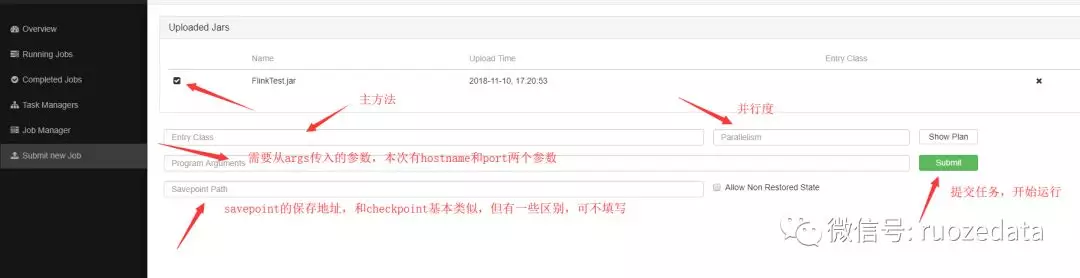
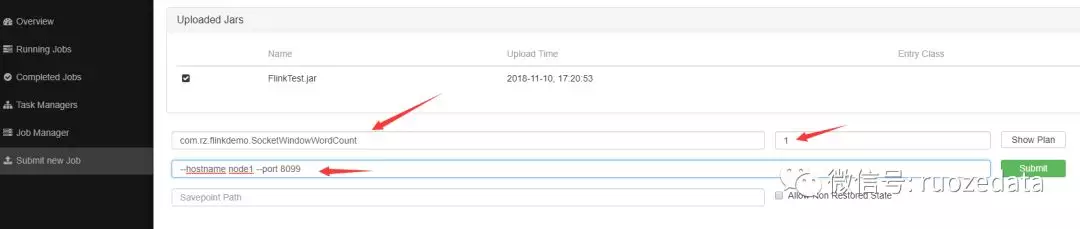
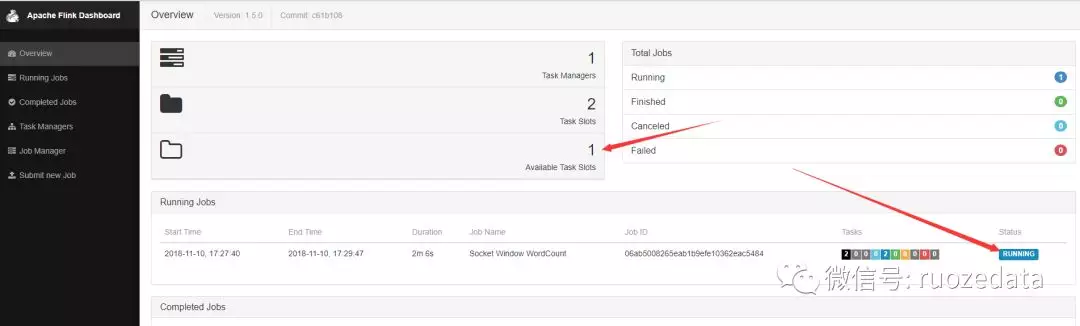
提交结束之后去overview界面看,可以看到,可用的slots变成了一个,因为我们的socket程序占用了一个,正在running的job变成了一个
发送数据
1 | [root@hadoop000 flink-1.5.0]# nc -l 8099 |
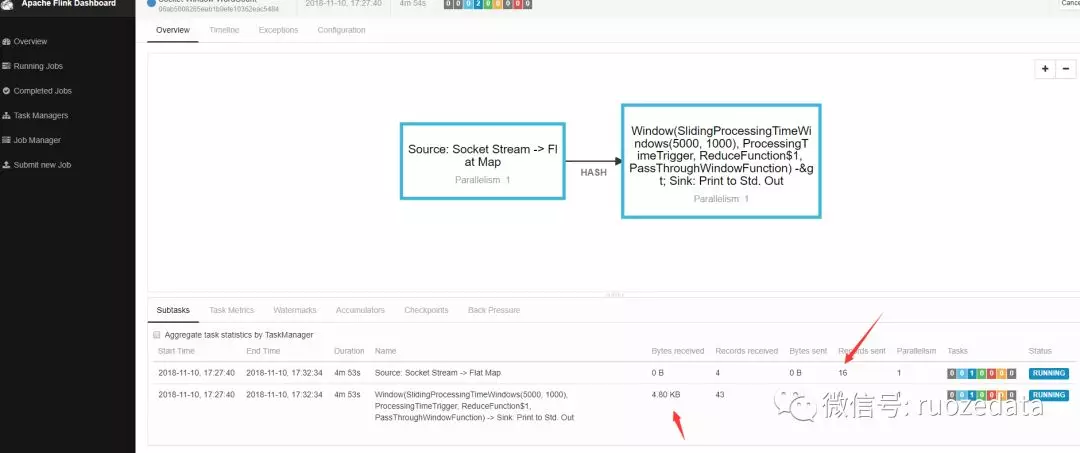
点开running的job,你可以看见接收的字节数等信息
到log目录下可以清楚的看见输出
1 | [root@localhost log]# tail -f flink-root-taskexecutor-2-localhost.out |
除了可以在界面提交,还可以将jar上传的linux中进行提交任务
运行flink上传的jar
1 | bin/flink run -c com.rz.flinkdemo.SocketWindowWordCount jars/FlinkTest.jar --port 8099 --hostname node1 |
其他步骤一致。
8.使用kafka作为source
加上依赖
1 | <dependency> |
1 | public class KakfaSource010 { public static void main(String[] args) throws Exception { |
9.使用mysql作为sink
flink本身并没有提供datastream输出到mysql,需要我们自己去实现
首先,导入依赖
1 | <dependency> |
自定义sink,首先想到的是extends SinkFunction,集成flink自带的sinkfunction,再当中实现方法,实现如下
1 | public class MysqlSink implements |
这样实现有个问题,每一条数据,都要打开mysql连接,再关闭,比较耗时,这个可以使用flink中比较好的Rich方式来实现,代码如下
1 | public class MysqlSink extends RichSinkFunction<Tuple2<String,String>> { private Connection connection = null; private PreparedStatement preparedStatement = null; private String userName = null; private String password = null; private String driverName = null; private String DBUrl = null; public MysqlSink() { |
Rich方式的优点在于,有个open和close方法,在初始化的时候建立一次连接,之后一直使用这个连接即可,缩短建立和关闭连接的时间,也可以使用连接池实现,这里只是提供这样一种思路。
使用这个mysqlsink也非常简单
1 | //直接addsink,即可输出到自定义的mysql中,也可以将mysql的字段等写成可配置的,更加方便和通用proceDataStream.addSink(new MysqlSink()); |
10.总结
本次的笔记做了简单的部署、测试、kafkademo,以及自定义实现mysqlsink的一些内容,其中比较重要的是Rich的使用,希望大家能有所收获。
