1.将之前打包的jar包上传
[root@sht-sgmhadoopnn-01 spark]# pwd
/root/learnproject/app/spark
[root@sht-sgmhadoopnn-01 spark]# rz
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring sparkdemo.jar…
100% 164113 KB 421 KB/sec 00:06:29 0 Errors
2.以下是错误
2.1
1 | ERROR1: Exception in thread "main" |
IDEA打包的jar包,需要使用zip删除指定文件
1 | zip -d sparkdemo.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF |
2.2
1 | ERROR2: Exception in thread "main" java.lang.UnsupportedClassVersionError: com/learn/java/main/OnLineLogAnalysis2 : Unsupported major.minor version 52.0 |
yarn环境的jdk版本低于编译jar包的jdk版本(需要一致或者高于;每个节点需要安装jdk,同时修改每个节点的hadoop-env.sh文件的JAVA_HOME参数指向)
2.3
1 | ERROR3: java.lang.NoSuchMethodError: com.google.common.base.Stopwatch.createStarted()Lcom/google/common/base/Stopwatch; |
抛错信息为NoSuchMethodError,表示 guava可能有多版本,则低版本
1 | [root@sht-sgmhadoopnn-01 app]# pwd |
3.后台提交jar包运行
1 | [root@sht-sgmhadoopnn-01 spark]# |
4.yarn web界面查看运行log
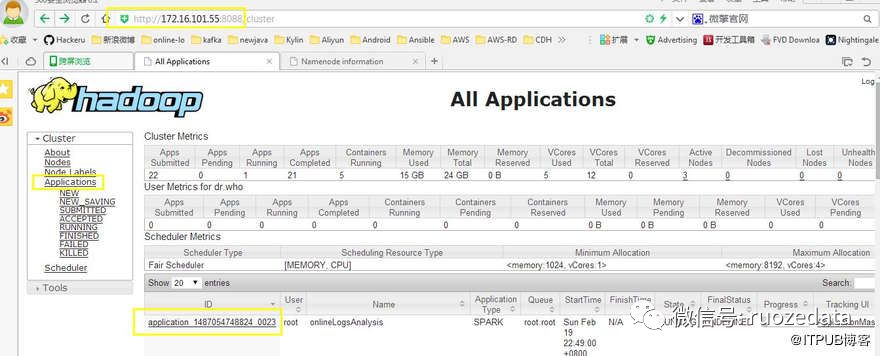
ApplicationMaster:打开为spark history server web界面
logs: 查看stderr 和 stdout日志 (system.out.println方法输出到stdout日志中)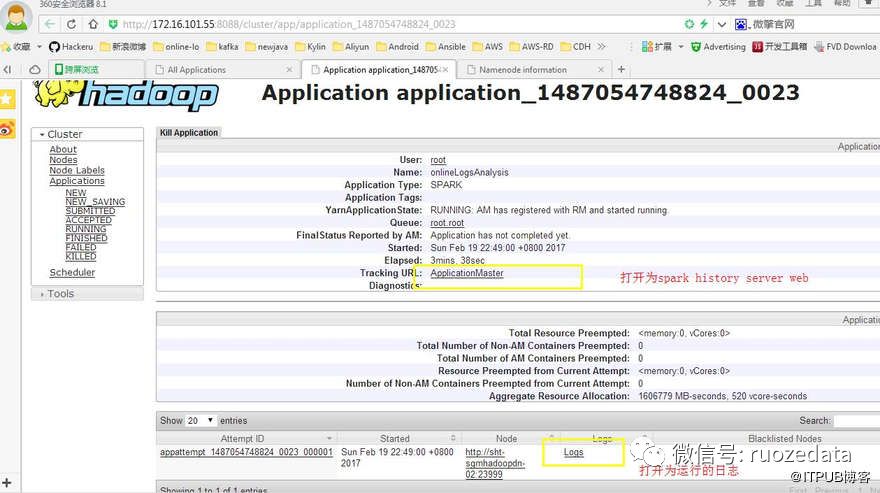


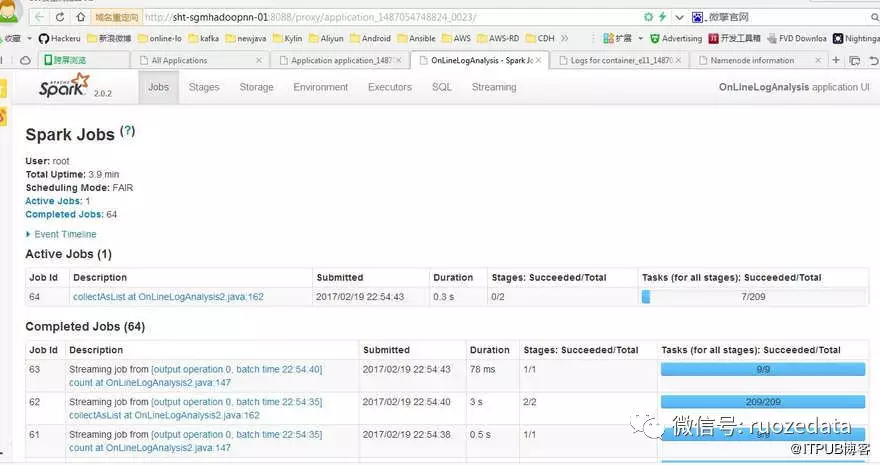
5.查看spark history web
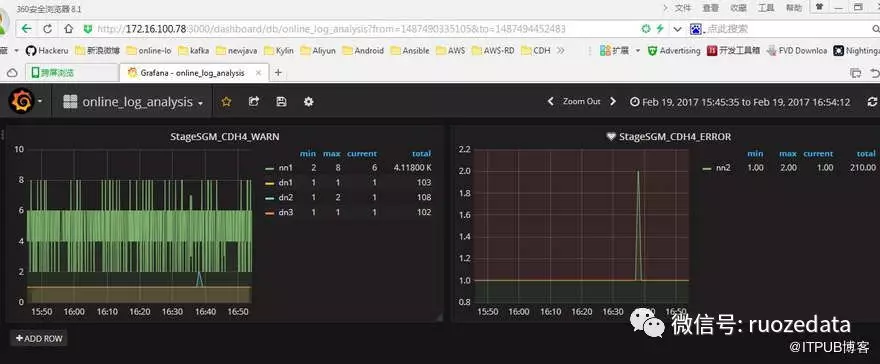
6.查看DashBoard ,实时可视化