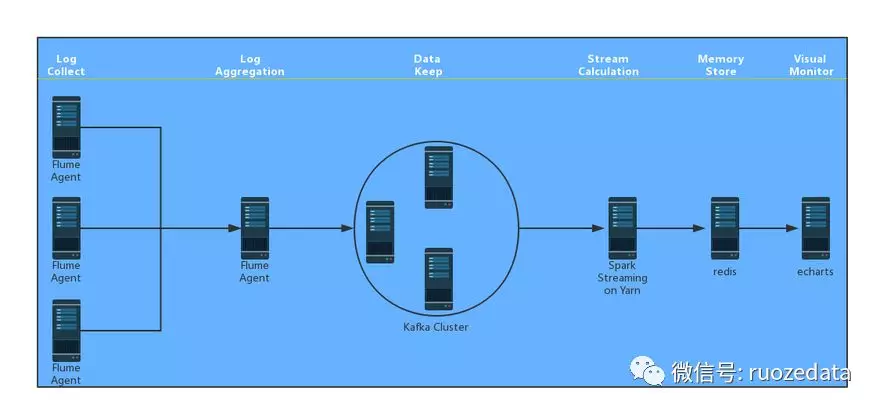
1.前期基本架构图
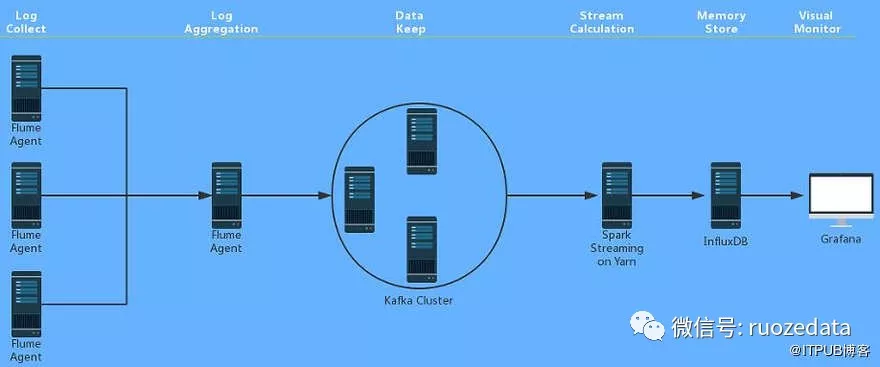
2.最终基本架构图
3.版本
| 组件 | 版本 |
|---|---|
| Flume: | 1.7 |
| Hadoop: | 2.7.3 |
| Scala: | 2.11 |
| Kafka: | 0.10.1.0 |
| Spark: | 2.0.2 |
| InfluxDB: | 1.2.0 |
| Grafana: | 4.1.1 |
| maven: | 3.3.9 |
4.主要目的
主要是想基于Exec Source开发自定义插件AdvancedExecSource,将机器名称 和 服务名称 添加到cdh 服务的角色log数据的每一行前面,则格式为:机器名称 服务名称 年月日 时分秒.毫秒 日志级别 日志信息 ;
然后在后面的spark streaming 实时计算我们所需求:比如统计每台机器的服务的每秒出现的error次数 、统计每5秒的warn,error次数等等;
来实时可视化展示和邮件短信、微信企业号通知。
其实主要我们现在的很多监控服务基本达不到秒级的通知,都为5分钟等等,为了方便我们自己的维护;
其实对一些即将出现的问题可以提前预知;
其实最主要可以有效扩展到实时计算数据库级别日志,比如MySQL慢查询日志,nginx,tomcat,linux的系统级别日志等等。
5.大概流程
1.搭建hadoop cluster
2.eclipse 导入flume源代码(window7 安装maven,eclipse,eclipse与maven集成)
3.开发flume-ng 自定义插件
4.flume 收集,汇聚到hdfs(主要测试是否汇聚成功,后期也可以做离线处理)
5.flume 收集,汇聚到kafka
6.搭建kafka monitor
7.搭建 spark client
8.window7装ieda开发工具
9.idea开发 spark streaming 的wc
10.读取kafka日志,开发spark streaming的这块日志分析
11.写入influxdb
12.grafana可视化展示
13.集成邮件
###说明:
针对自身情况,自行选择,步骤如上,但不是固定的,有些顺序是可以打乱的,例如开发工具的安装,可以一起操作的,再如这几个组件的下载编译,如果不
想编译可以直接下tar包的,自行选择就好,但是建议还是自己编译,遇到坑才能更好的记住这个东西,本身这个项目就是学习提升的过程,要是什么都是现成的,
那就没什么意义了
