一.需求
按照不同部门作为分区,导数据到目标表
二.使用静态分区表来完成
71.创建静态分区表:
1 | create table emp_static_partition( |
2.插入数据:
1 | hive>insert into table emp_static_partition partition(deptno=10) |
3.查询数据:
1 | hive>select * from emp_static_partition; |

三.使用动态分区表来完成
1.创建动态分区表:
1 | create table emp_dynamic_partition( |
2.插入数据:
1 | hive>insert into table emp_dynamic_partition partition(deptno) |
需要设置属性的值:
1 | hive>set hive.exec.dynamic.partition.mode=nonstrict; |
假如不设置,报错如下:
3.查询数据:
1 | hive>select * from emp_dynamic_partition; |
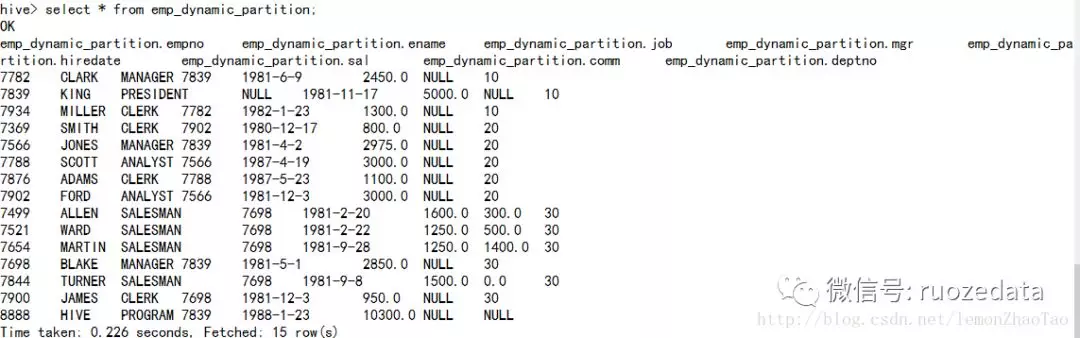
分区列为deptno,实现了动态分区
四.总结
在生产上我们更倾向是选择动态分区,
无需手工指定数据导入的具体分区,
而是由select的字段(字段写在最后,有几个写几个)自行决定导出到哪一个分区中, 并自动创建相应的分区,使用上更加方便快捷 ,在生产工作中用的非常多多。
