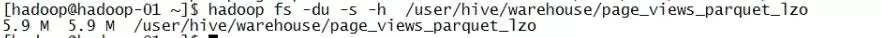你们Hive生产上,压缩和存储,结合使用了吗?

1. ORC+Zlip结合
1 | create table page_views_orc_zlib |
用ORC+Zlip之后的文件为2.8M

###### 2. Parquet+gzip结合
1 | set parquet.compression=gzip; |
用Parquet+gzip之后的文件为3.9M

3. Parquet+Lzo结合
3.1 安装Lzo
1 | wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz |
3.2 安装Lzop
1 | wget http://www.lzop.org/download/lzop-1.03.tar.gz |
3.3 软连接
1 | ln -s /usr/local/hadoop/lzop/bin/lzop /usr/bin/lzop |
3.4 测试lzop
lzop xxx.log
若生成xxx.log.lzo文件,则说明成功
3.5 安装Hadoop-LZO
1 | git或svn 下载https://github.com/twitter/hadoop-lzo |
3.6 配置
在core-site.xml配置
1 | <property> |
3.7 测试
1 | SET hive.exec.compress.output=true; |
用Parquet+Lzo(未建立索引)之后的文件为5.9M